A collection of independent software and hardware components networked together and communicating to achieve a common goal to deliver one or more business functionality is the main behavior of distributed software architecture. The distributed nature of the components allows to scale each component interdependently while being fault tolerant, because unavailability of a single component will not impact the whole system functionality. Moreover isolated processing of each component will increase maintainability of the whole system.

There is nothing of the sort called correct architecture for a distributed system and it is decided by a qualified architect along with the necessary justifications based on the given context, feasibility, budget and many other technical and non-technical factors.
However there are different set of architecture styles available in general to implement distributed software architecture and each style exist with its own pros and cons. We will discuss those primary distributed software architecture styles along with their trade-offs.
Microservices Architecture
When each of the component in distributed architecture is complying to the principal of single-responsibility and they are independently deployed along with it’s own data complying to the share nothing principal, a mesh of microservices will be created.
Microservices will get invoked via an API gateway by their consuming clients to preserve a single entry point and a central control of other cross-cutting concerns such as security and auditing. And inter-microservices communication will be conducted through microservice network and API interfaces.
In order to further optimize the internal API calls, all microservices will be registered in shared configuration called a service registry. The service registry will hide the network configuration complexity of microservices by exposing a network identifier (IP / port) to service-name mapping where a microservice will be discovered by other microservices using the service name.
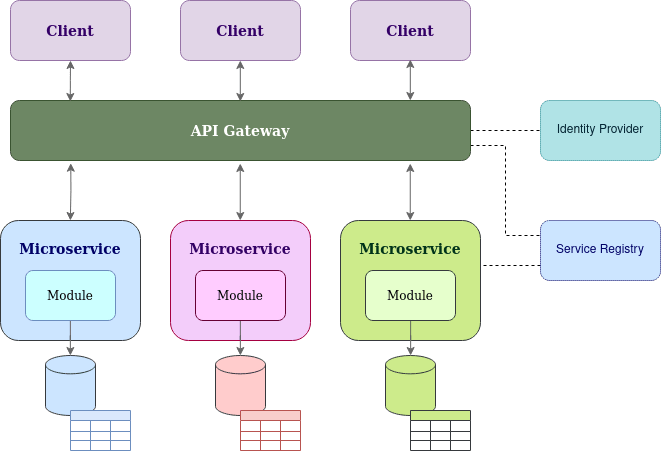
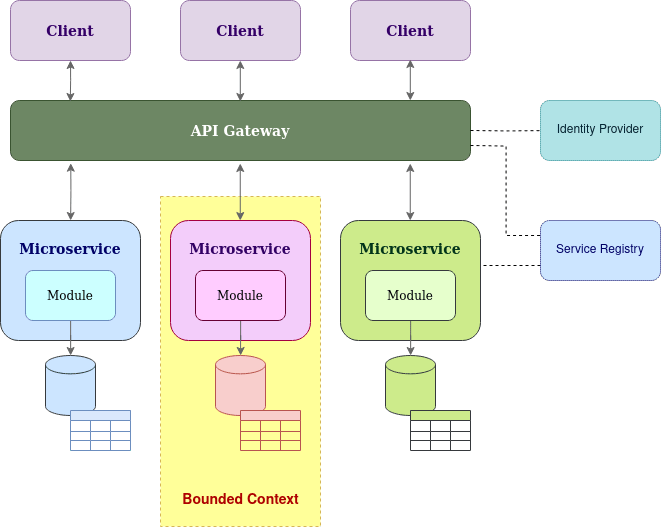
As mentioned above, one of the primary principal in microservice is complying to share nothing principal which is resembled by the concept of bounded-context. And a microservice will be the sole owner of it’s service and data within it’s bounded-context and the only way to access or modify data is via the exposed API interface of the microservice.
One of the advantage in this architecture is independent deployment of components without impacting other business functions of the system. Further the components are able to achieve scalability and elasticity of specific business functions based on the demand which will result in saving unnecessary hardware and network resource consumption. Microservices are able to achieve service level resiliency by adopting patterns such as circuit-breaker, bulk-head to make the architecture fault tolerant. And this decoupled nature of services increase maintainability and testability of individual services.
And there are some trade-offs to be considered before continue with microservices architecture where this is not suitable for course grained services and it performs well with fine grained services. Moreover this need more cultural changes from development and testing team perspective if the team culture is developed by engaging with monolith software systems in the past. Over the time communication complexity will be added when more microservices are added in to the architecture. Therefore it is important to follow clear grouping of business functions into their specific domains when defining new services to reduce unnecessary inter-microservice communication which is also known by the term of ‘Distributed Big Ball of Mud’.
Service Based Architecture
When there are clusters of modules with clear domain separation it depict characteristics of this architecture where the system is composed of domain services by consuming a central monolith data store. Those domain services can be accessed via single or multiple API / UI components by it’s consuming clients.

And this architecture is able to evolve further to separate modules in to independent microservices, if independent scalability and elasticity is expected on specific business functions. And it will compose a hybrid architecture by combining best features of microservices and service-based architecture by making it more pragmatic. Further this architecture could be logically separated in to individual units which will be more manageable and it will be a low risk approach when migrating to microservices architecture.

This architecture can be identified in systems when the data is preserved as large monolith and centralized where it is consumed by coarse-grained services. And the course grained services are independently deployed with all of its modules.
And it is important to maintain limited number of domain services to avoid excessive inter-communication of services in order to maintain less complicated system by preserving high performance. Although the domain services are capable of scaling independently regardless of which module requires scalability, the whole domain will scaled consuming unnecessary computing resources.
Service Oriented Architecture
This architecture allows to re-use loosely coupled Business Services to build Enterprise Service capabilities while decoupling point to point service integrations in synchronous communication. These Business Services can be public external services such as Google Maps, Facebook Auth or an internal service such as a Customer Service, which are complying with different protocols and data models. And this point to point inter-service integration complexity within an enterprise software system is simplified by using an Enterprise Service Bus (ESB) within this architecture. And a consumer can request data from ESB following the contract defined by the ESB without dwelling on to the integrated business service by implementing any data or protocol transformation tasks.
High-level component interaction in SOA software architecture is illustrated in the below diagram.
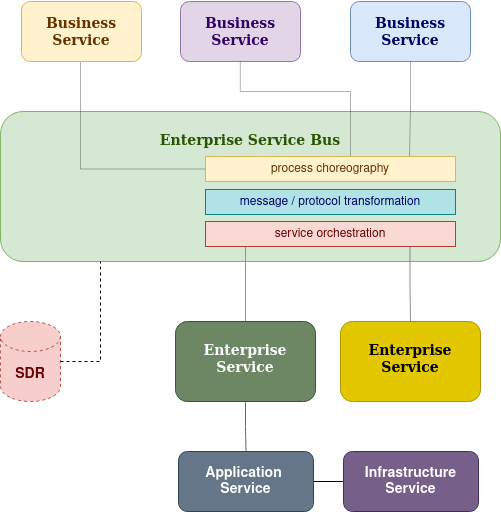
An ESB is capable of providing further more features to handle the integration complexity such as routing requests and responses, transforming protocols and message formats, enhance messages are some of the features. And other two important components are Process-Choreography which use multiple Business Services to provide expected business functionality and the Service-Orchestration which integrate processed Business Service output with coarse grained enterprise services.
Further ESB has a Service Description Repository (SDR) which used to provide details of services integrated with ESB, specially the external services. And additionally an ESB will suffice non-functional aspects as well such as security, monitoring and logging for the messages communicated through the ESB.
In order to ensure security of the implemented SOA system the service consumers are often integrated through an API gateway as in below diagram. Further multiple ESBs could be used to increase availability of the SOA system and a load balancer will be required to distribute load from service clients.

Over the time a SOA implementations could get more complicated and maintenance will be one of the challenge in enterprise systems. Further it will require considerable time and cost to start a new SOA implementation due to it’s initial configuration effort and cost of ESB software systems.
Although this architecture style has been blotting out and mostly overtaken by microservice and event-driven architecture styles there are some advantages packaged with SOA systems. This architecture brings more abstraction to the synchronous service communications with some extent of fault-tolerance and it provides high interoperability to heterogeneous business services.
Event-Driven Architecture
With the popularity of microservices, event-driven systems are getting much popularity in modern software architecture. The event-driven systems consume an event from an event triggering service (event source) such as an update in database, new message in queue or Kafka topic, an API call or even an event generated by cron scheduler.
And this event will be consumed by an event processor to process the business workflow in asynchronous execution pattern. And those event processor services are completely decoupled.
There are different patterns available to implement event driven architecture such as using SAGA patterns where after completion of processing an event, the event processor will send a message to a message queue. Then that new message event will be consumed by subsequent services until end of the business process execution. When there are many services involve in the process, the implementation will be complex and difficult to troubleshoot when something is gone wrong. Moreover testing of end to end business scenarios will be challenging due to its distributed nature. However since this is completely asynchronous this pattern will have reduced latency concerns related to availability, performance and fault-tolerance.
Following diagram depicts a basic execution of SAGA pattern in event-driven architecture.

And another pattern is to use a task orchestration engine to execute the business process as a workflow. And this will be some what near real-time compared to the SAGA pattern based on what orchestration tool is used for the execution.

The above diagram depicts a high-level execution of a task orchestrator, and the task processors will be fully independent of the business workflow logic since it is controlled by the orchestration server. As a result of this, changes to the business process will not require (or minor changes) on the task processors compared to SAGA. However the orchestration service will be a single point of failure if it is not designed to ensure high availability and fault tolerant when defining orchestrator architecture along with its deployment strategy.
Space-Based Architecture
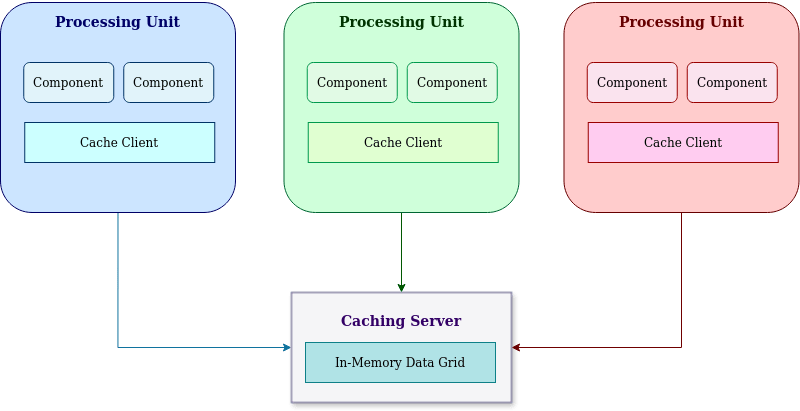
This architecture is based on shared memory space across Processing Units. A processing unit is composed of software Components, In-Memory Data Grid (cache) and a Data Replication Engine.
Each processing unit is able to function independently by consuming shared memory grid which is constantly replicated by the Data Replication Engine across all the processing units. And these processing units are highly scalable and fault-tolerant. In the event of failing a single processing unit subsequent requests will be routed to another replica of the processing unit since it has shared data in the data-grid.
Further these processing units could be logically separate in to their specific domains to distribute responsibilities across the domains. And the high-level components available in space based architecture are depicted in the following diagram.

Maintenance of infrastructure is handled by the Virtualized Middleware, and it is composed of four services such as Messaging Grid, Data Grid, Processing Grid and Deployment Manager.
The Messaging Grid is responsible of handling input requests from clients and manage session state of the clients. Further it will decide to which Processing Unit the request should be routed to process.
In-memory data grid which is distributed across all processing units will be in sync all the time via it’s data replication engine. Data Grid service on the Virtualised Middleware will coordinate the data synchronization via Data Replication Engines in each Processing Unit. Furthermore, the changes in memory layer of each individual Processing Unit will be written in to a persistent storage via Data Pumps to be used as a backup in the event of memory layer recovery. This is achievable with following Change-Data-Capture (CDC) pattern and the data changes made by software components will be eventually persisted on to the desired persistent data store.
Processing Grid is an optional component in this architecture where it will be required when a request depends on multiple Processing Units to process a request. And Processing Grid will orchestrate execution of processing units as per the business functionality.
Dynamic maintenance of Processing Units are handled by the Deployment Manager and it will monitor throughput and latency continuously and act as an auto-scaling agent. This feature enables to achieve high scalability and availability in this architecture.
By design this architecture provides high scalability and performance along with elasticity due to the shared memory space, and this is more suitable for high throughput low latency applications which expects extra high application response and performance.
The maintenance of this architecture will be challenging due to replicated memory layer and the cost may be high based on the distributed cache engine used with this architecture implementation. And the cache replication will add more complexity when more processing units are added in to the system.
Further the memory replication complexity could be reduced by centralizing the memory data grid, however it will add additional network latency to the functions executed by the processing units and it is a trade-off to be decided based on business features, latency and performance expectations.
Conclusion
Generally software systems are composed with combination of different architectures which is also known as hybrid architecture style. And it allows to gain benefits from each architecture style and avoid any trade-offs added in to the architecture.
However it is vital to understand differences and capabilities of each style when developing a software architecture which will result in delivering an efficient and performant software system while reducing unnecessary cost involve with development, test, operational, maintenance and infrastructure.
