Application Programming Interface (API)
An API is a collection of services available over specific protocol for the purpose of Inter communication between software systems, sub-systems or system components.
As per Wikipedia the API is defined as; “In computer programming, an application programming interface (API) is a set of subroutine definitions, communication protocols, and tools for building software. In general terms, it is a set of clearly defined methods of communication among various components. A good API makes it easier to develop a computer program by providing all the building blocks, which are then put together by the programmer.”
In an API there will be many consumers of it’s services as some of them are depicted in above diagram. It is more important to design the API suitable for all the consumers to make it convenient to use while avoiding potential threats on the API.
History in a nutshell
The need of API was evologing from time that the distributed computing has started where interacting of a single software system was a need from multiple geographic locations over different communication protocols over different hardware devices. Let’s have a look as some of the early technologies that are being used in distributed systems.
RPC (Remote Procedure Call)
This is a protocol which is used to invoke function in another computer without understanding the network details of communication. This concept was initiated at early 70s and there are many implementations available based on RPC.
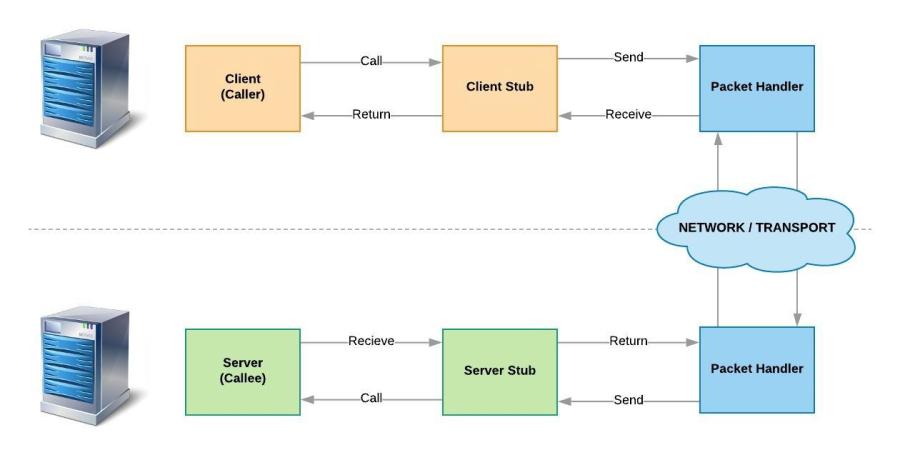
Java-RMI (Remote Method Invocation)
The RMI (Remote Method Invocation) is an RPC implementation complying to object-oriented programming paradigm which provided a mechanism to create distributed application for Java based software systems. The RMI allows an object to invoke methods on an object running in another JVM on a different remote computer over stub and skeleton. Client communication with the server would be done by the stub which marshaling the outgoing request and unmarshalling the incoming request from the actual remote object. The skeleton is the remote object which accepts and unmarshal the request and send the response to stub after marshaling the response. Apart from RPC general protocol there is an additional layer added in RMI which is RRL (Remove Reference Layer) which is handling the ‘liveliness’ of the remote objects while handling communication between client and server.

There are couple of other technologies were introduced over the same protocol with different implementations such as CORBA (Common Object Request Broker Architecture), RMI-DCOM.
RPC is not much popular technology as of today due to couple of limitations that it had experienced. Distributed computing is fundamentally different than local computing where the distributed computing relies over network hardware infrastructure and local computing relying on general computer architecture. The attempt in RPC was to not concentrate on these differences, and invoke remote calls just as local function calls. And there are couple of limitations that could be listed which could cause RPC to unpopular.
- Communicating systems has to be built over same technology
- Effort is high in implementing and maintaining of stub and skeleton over a network with network changes
- Unavailability of ports since firewalls block most of the ports other than HTTP which is often open
- The network is not reliable, there should be retry mechanism such as in HTTP
- The size of the object communicated matters as network bandwidth is costly
- The network has to be secure since the protocol does not have default security mechanism
API Today
SOAP vs REST
SOAP and REST are two different API styles that approach the communication among systems differently.
SOAP (Simple Object Access Protocol)
This is a standardized protocol that sends messages using other protocols such as HTTP or SMTP.
The SOAP specification is maintained by W3C (World Wide Web Consortium) as a general web application standard. Unlike RPC SOAP is composed with advanced security features such as ACID compliance and authorization. SOAP services are defined in WSDL (Web Services Description Language) in comprehensive manner and the UDDI (Universal Description, Discovery and Integration) which maintains a registry of services for service discovery. In addition to that it uses XML as the communication message language which is known as a native inter-operable language. The SOAP message is composed with below segments;
- SOAP Envelope – Defines the start and end of the message.
- SOAP Header – Hold any optional elements to be used when processing the message such as authentication tokens.
- SOAP Body – The actual message content to be communicated.
- SOAP Fault – Any errors encountered during the message processing to be communicated.
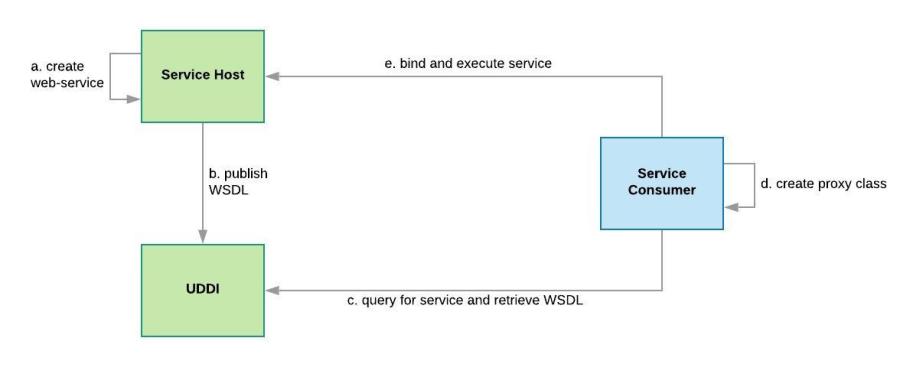
There are couple of extensions are available in SOAP to solve specific concerns such as WS-Security for message security, WS-I to solve the interoperability issues pertained with SOAP, WS-AtomicTransaction for ACID properties of transactions, WS-Coordinator to enable communication between heterogeneous systems operate over different protocols etc.
Unlike SOAP, REST is an architectural style and not specifically a protocol. Hence REST architecture is defined with set of general guidelines that is need to be followed for the better use of RESTful web services.
REST – Representational State Transfer
In 2000, Roy Fielding proposed Representational State Transfer (REST) as an architectural approach to designing web services. In a nutshell REST is an architectural style to enable communication between remote software systems in distributed computing or internal components of a software system which is based on hypermedia. Since it is based on HTTP, it is designed around resources such as Objects, Data and Services where they are uniquely identifiable by an URI (Uniform Resource Identifier). And the REST based communications are stateless and this enable to operate each service as an atomic operation which enables the ability to scale independently.
Characteristics of a well-designed API
In general a well designed and engineered API should have following characteristics.
- Easy to Read and Operate: A well designed API would be easy to operate, and its resources and associated operations can quickly be understood by developers who work with it constantly.
- Avoid Incorrect Use: A well designed API’s would be self descriptive and provide adequate guidelines on usage with comprehensive examples. Hence the probability of incorrect usage would be very minimal.
- Complete and Concise: API could be able to consume to the maximum to build full-fledged enterprise applications with the data exposed over the APIs. However the completeness is achieved overtime as the API is continue to mature with the refinement over versions.
In order to make an API a well-designed, following guidelines are recommended to be followed;
Keep It Simple

A simple API would be able to understand by a developer without referring to specific documentation which express the functionality of the API. There are couple of things which serves the needful such as;
- Use simple and human readable text in the URL and Parameters
- Follow a standard which is defined for the API across all the URLs, Parameters and Header values
- Make sure the same result is not returned via multiples services which could cause complications.
- Provide exact definition of each parameter in few words
- Provide sample payload of each service executable via curl or any service client utility
Nouns over Verbs

Avoid using verbs to name services since it would create multiple routes to the same resource which would complicate the API.
Some of the inappropriate routes;

Better use of noun for the service naming which could make the API much more simplified.

Once a single noun is used to invoke CRUD operations over a single resource it makes the API more understandable and reduce the probability of making erroneous implementation as it is pattern that repeats over all the resources the delivers over the API.
Further it is advisable to stick to either plural or singular naming for the services rather mixing the naming conventions. However it would make more meaningful when the service names are in plural such as;
- /cars instead of /car
- /users instead of /user
Sub-resources for Relationships

There are relationships between resources where the data would need to be retrieved based on the relationships over querying. Use of sub-resources for relationships reduce the number of network calls to get the required data.
To get the information over relationships of resource and it is would helpful to reduce the number of network calls to get the data which would be a factor to increase performance of the transaction.
![]()
In order to perform operations with each objects the relationships could be leveraged as in below;
Create a post by user 235

Create a comment by user 235 on the post 789

Get all the comments on post 780

Follow Standard HTTP Methods

Rest is an architectural practice which is based on HTTP protocol and the protocol itself provides an inbuilt functionality to use appropriate method to execute transaction which could enhance clarity of service usage and reduce mis-usages.
Following methods are usable in APIs which are available in HTTP;
GET – Request an object or objects available in a server
POST – Usually used to create a new object on the server, in some instances update and create both facilitated by this method
PUT – Used to replace the current object
DELETE – Make the object unavailable to retrieve over GET. It may be permanent deletion or inactivating the object on server.
PATCH – Similar usage as PUT, however by definitions this is referring to partial update of the object, not replace.
| Resource | POST | GET | PUT | PATCH | DELETE |
| /customers | Create a new Customer object | Retrieve all Customer objects | Bulk update of Customer objects | Bulk partial update of Customer | Remove all Customer objects |
| /customers/1 | Error – Not used to define the ID | Retrieve the object for Customer ID 1 | Update the object reflect Customer ID 1 if it exists | Partial update of object at Customer ID 1 if exists | Remove object reflects customer ID 1 |
| /customers/1/orders | Create a new Order object for Customer ID 1 | Retrieve all Order objects for Customer ID 1 | Bulk update of Order objects at Customer ID 1 | Bulk partial update of Order objects at Customer ID 1 | Remove all Order objects for Customer ID 1 |
This also supports for the theory of One resource – One URL, where all the operations related to a resources are available over a single URI and the operation is deferred by the HTTP method which is used.
An API Services should be Idempotent
Consumers of the API could intentionally or unintentionally would execute APIs mistakenly. And these mistaken API calls should not leave the data beneath the API unstable.
Usually following methods are idempotent by default;
GET, PUT, PATCH, DELETE
Even Though service calls at above methods executes multiple times only the updated date would get changes while remaining other data unchanged. Service calls over DELETE method would return 204 (No Content) instead 200 OK on subsequent invocations.
POST
If the POST method is invoked n number of times on the API, there would be n number of objects in the data store beneath the API if duplication is not addressed over the API. There are several approaches to avoid replay of POST service calls.
- Use unique field in the data-store
- Use unique HATEOAS which is also known as ‘Post Once Exactly’ (https://tools.ietf.org/html/draft-nottingham-http-poe-00)
- Restrict replay of same request at Network perimeter
Use of HTTP Headers
Both, client and server, need to know which formats and standards are used for the communication. The format has to be specified in the HTTP-Header. So the chances of attempting to deserialize the message over incorrect format would be reduced as it allows to content negotiation between server and the client.
Content-Type defines the request format.
- Application
- application/json
- application/xml
- application/javascript
- application/pdf
- application/x-www-form-urlencoded
- application/x-shockwave-flash
- Audio
- audio/mpeg
- audio/x-wav
- audio/x-ms-wma
- Images
- image/gif
- image/jpeg
image/png
image/tiff - image/x-icon
- Multipart
- multipart/mixed
multipart/alternative
multipart/related (using by MHTML (HTML mail).)
multipart/form-data
- multipart/mixed
- Text
- text/css
text/csv
text/html - text/plain
- text/xml
- text/css
- Video
- video/mpeg
- video/mp4
- video/quicktime
- video /webm
- Font
- font/ttf
- font/otf
- font/collection
Accept defines a list of acceptable response formats.
The Accept request HTTP header defines which content types, expressed in MIME types (Multipurpose Internet Mail Extensions) where the client is able to understand and the values are presented in comma separated values. Using content negotiation, the server then selects one of the best suite proposal sent by client and uses it and informs the client of its choice with the Content-Type response header.
Accept-Encoding should be defined if any encoding is used to compress the message which would enhance the performance of communication as it shrinks the size of the data transmitted.
Accept-Charset would define the charset to be used to decode the payload where the server and client could agree on supported charset in the content negotiation.
Use HATOAS

Hypermedia as the Engine of Application State is a principle that hypertext links should be used to create a better navigation through the API.
A usual Student entity

A usual json representation

A HATEOAS based response

Filtering

There are many practices followed in getting a filtered result from an API which is retrieved over a defined query.
Equals
GET /cars?color=red ;
This would returns a list of red cars
Other Operators
Other than equals there would be many other operators used in a query language such as >, <, !, exist, like etc. A particular format could be followed as follows;
Use an alphanumeric syntax for operators

The filters would be defined in a filters parameter where it would be convenient to identity all the filters at the server side rather check on each parameter in the URL to find filter criteria.
GET /cars?filters=[seats[lt]=4] ;
This query would return a list of cars which has maximum of 4 seats.
GET /cars?filters=[seats[lt]=4&model[like]=sed] ;
This query would return a list of cars which has maximum of 4 seats and the model starts with ‘sed’ characters.
The advantage is that it would not require any specific URL encoding to decode the operators at the client end, however to convert the square bracketed operators at server side there are many libraries available.
Sorting

In order to retrieve a sorted result from an API following syntaxes would be followed similar in Filtering.

GET /cars?sort=[dec]manufacturer ;
This will return list of cars sorted in descending order.
In order to define complex sorting queries comma separated values could be used.
GET /cars?sort=[dec]manufacturer,[asc]model ;
This query would return list or cars descended by manufacturer and ascended by the model.
Field Selection

There could be occasions that the client would require a limited number of attributes of the resource in order to save on bandwidth and the client resources such as in mobile applications. A field selection of the response would be able to cater this requirement as per below example;
GET /cars?response_fields=manufacturer,model,id,color
Pagination

Limiting of response payload would save network bandwidth as well as the client would be able to get the result suitable to the capacity that client could handle.
There are couple of approaches paginating a data-set within APIs.
1. Offset Pagination
As the simplest method of pagination this will based on Limit and Offset set by the client when consuming the API.
GET /cars?offset=100&limit=20 ;
This query would return the 20 rows starting with the 100th row of the cars API.
In DB ;
SELECT * FROM car
ORDER BY manufacture
LIMIT 20
OFFSET 100;
Links to the next or previous page should be provided in the HTTP header link as well. It is important to follow this link header values instead of constructing your own URLs.
next – <https://mytechblogs.com/sample/api/v1/cars?offset=15&limit=5>; rel=”next”,
previous – <https://mytechblogs.com/sample/api/v1/cars?offset=5&limit=5>; rel=”prev”,
last – <https://mytechblogs.com/sample/api/v1/cars?offset=50&limit=3>; rel=”last”,
first – <https://mytechblogs.com/sample/api/v1/cars?offset=0&limit=5>; rel=”first”,
Very less amount of coding effort would be in Offset pagination where on the server it would be stateless and this would work regardless of filter and sort criteria.
This is not a perfect performant when there are larger offsets where to count the offset the storage media would have to skip the large offset just to count the number or records. And when records are getting added the a page drift would noticed since the client would be invoking the API with the last known offset.
Offset Pagination would be suitable when querying data from master tables where there are low record writing frequency.
2. Keyset Pagination
Due to the limitations in Offset pagination, Keyset could be used where client will not request the second page from server instead it will request for the next-page.
This could be achieved from using indexed column as a filter parameter where the last parameter sent to the client will have to return by client in return when requesting for the next-page. One suitable parameter is the created or modified date of the resource on the database which works most of the time.
GET /cars?limit=20&created=[lte]2019-03-01T00:00:00 ;
If the client realized the the minimum created date is ‘2019-03-01T00:00:00’, it will calling the API with the date filtration.
In DB;
SELECT * FROM car
WHERE created <= ‘2019-03-01T00:00:00’
ORDER BY manufacture
LIMIT 20
This would not drift the pages even new records are added to the table and the drawback is the tight coupling to filtration and sorting on the API where the client has to provide the filter parameter which is the created-date even the client is not intended to filter the result.
Links to the next or previous page should be provided in the HTTP header link as well. It is important to follow this link header values instead of constructing your own URLs. However to calculate first and last the server has to provide the logic as the client is only aware of the maximum or minimum updated record in the current page.
next – <https://mytechblogs.com/sample/api/v1/cars?limit=20&created=%5Blte%5D2019-03-01T00:00:00>; rel=”next”,
previous – <https://mytechblogs.com/sample/api/v1/cars?limit=20&created=%5Blte%5D2019-02-28T00:00:00>; rel=”prev”,
last – <https://mytechblogs.com/sample/api/v1/cars?limit=20&created=%5Blte%5D2019-03-02T00:00:00&page=last>; rel=”last”,
first – <https://mytechblogs.com/sample/api/v1/cars?limit=20&created=%5Blte%5D2019-03-02T00:00:00&page=first>; rel=”first”,
3. Seek Pagination
Seek Pagination is an extension of Keyset Pagination where Seek would consume a unique and indexed id of a record to define the page. It is not suitable where custom sorting queries are present on the API since this best works without any coupling on filtering and sorting mechanism.
GET /cars?limit=20&after_id=20 ;
When the client realizes that the last unique ID of the last record of the previous page is 20 and this will return next 20 records starting from ID : 20.
In DB;
SELECT * FROM car
WHERE id > 20
LIMIT 20
Links to the next or previous page should be provided in the HTTP header link as well. It is important to follow this link header values instead of constructing your own URLs. However to calculate first and last the server has to provide the logic as the client is only aware of the maximum or minimum updated record in the current page.
next – <https://mytechblogs.com/sample/api/v1/cars?limit=20&after_id=20>; rel=”next”,
previous – <https://mytechblogs.com/sample/api/v1/cars?limit=20&after_id=1>; rel=”prev”,
last – <https://mytechblogs.com/sample/api/v1/cars?limit=20&after_id=20&page=last>; rel=”last”,
first – <https://mytechblogs.com/sample/api/v1/cars?limit=20&after_id=20&page=first>; rel=”first”,
Both Keyset and Seek Pagination approaches are well performant in high page sizes.
Usually the total record count is return to client over the HTTP header : X-Total-Count.
Versioning the API

No versioning
APIs could be used without versioning and this would be applicable for internal routes where there are very low number of consumers. When there is any change in the API the consumers would have an impact where the consumers would need to adapt their implementation and perform testing in order to inline with the change.
GET /cars/54
URI versioning
When the API implementation is modifies a new version is introduced over the URI of the resource where the existing consumers of the API would not have any impact.


According to the above example there would be a change when consuming v1 to v2 of the API since the address has restructured in to sub-fields. HATEOAS are not included in this example and there will be two different HATEOAS will be generated for the same resource from multiple versions of API which could encounter complexities that has to handle properly.
Query string versioning
Instead of including version on the URI, a query parameter could be used to define the version of the API. Whenever the query parameter is not present a default version should be defined from server end. However there could be performance impact in some web-browsers and proxies as they are not caching the response from requests that include query strings in the URI.


Same complexity would exist in HATEOAS which was there in the URI versioning approach.
Header versioning
A custom header could be used to define the version of the API. Same as in Query String versioning a default version has to be associated when there is not any version present in the header.


When generating HATEOAS the header version has to be taken in to consideration as it tends to create multiple links for the same resource via multiple versions of the API.
Media type versioning
When the client is calling server which version of the payload could be specified over a common URI in the Accept headers in the request. Then the server would understand what services to be referred to process the request. Else the request would be ended up in error or corrupted data output.

When server responds to the request, it would decide the appropriate response to the client based on the server logic to handle multiple versions of media-types.

Error Handling and Response Messages

An API should be returning meaningful response to client in order to handle the error scenario properly and to make be aware of what needs to be fixed in order to correct the error. Since Restful APIs a are based on HTTP protocol, the standard HTTP response codes could be leveraged in order to respond to an error.
There are classification of response codes defined in HTTP specification which elaborates what is meant by each response code.
1XX – Informational
2XX – Successful
3XX – Redirection
4XX – Client Error
5XX – Server Error
Following are the frequently used success and error codes which are defined in the HTTP specification within the context of Restful APIs.
200 – OK – Success – success GET, PUT or POST request.
201 – OK – New resource created over POST or PUT
204 – OK – Resource was successfully deleted – DELETE method call which does not return any content
304 – Not Modified – Compared to If-Modified-Since : <timestamp> or If-Unmodified-Since : <timestamp> header param, the server will respond to use the client cached data which is already returned and no need to transfer again
400 – Bad Request – The request was invalid or cannot be served
401 – Unauthorized – User authentication is required to process the request
403 – Forbidden – The server understood the request and the user is authenticated, and the user may not have authorized to access the resource
404 – Not found – There is no resource mapped to the URI given
410 – Gone – The requested resource is no longer available or it is intentionally removed
422 – Unprocessable Entity – The server cannot process the entity
500 – Internal Server Error – An unexpected error in server which prevented processing the request
503 – Service Unavailable – The server is not available or it is undergone for maintenance
When returning errors it is advisable to send a descriptive json response where the client would have more understanding about the error and the clues to fix the error.
Sample Error Response:
HTTP/1.1 410 Gone
{
“errors”: [
{
“userMessage”: “Sorry, the requested resource was intentionally removed”,
“internalMessage”: “No car found in the database”,
“error-code”:”12345”
“more info”: “https://mytechblogs.com//api/v1/errors/12345”
}
]}
Rate Limiting

Rate limiting is important in APIs to control the usage from the clients in order to avoid unnecessary amount of load getting in to the system which would increase cost of deployment. There are couple of approaches to limit the access to API such as;
- Token Bucket or Leaky Bucket
- Fixed Window Counters
- Sliding Window Log
- Sliding Window Counters
Will be publishing algorithms involved in rate limiting over a separate blog post since it is a quite broader subject.
Allow Overriding HTTP

Some web proxies and firewalls have limitations where they will only be able to consume POST or GET methods only and other method calls would be discarded. As a solution to this X-HTTP-Method-Override header parameter could be used which is defined for the purpose of overriding the method. In a nutshell, the actual API call with correct method would be wrapped over GET or POST method and send to the API by the client. At the server end based on the value of X-HTTP-Method-Override header the actual method call is unwrapped and get executed within the server.
POST /cars/45 HTTP/1.1
Host: mytechblogs.com
Content-Type: application/json
X-HTTP-Method-Override: DELETE
Cache-Control: no-cache
Within server which would get executed is;
DELETE /cars/45
However there would be additional security threats due to overriding the HTTP method over header parameters where an external intruder would invoke legitimate services with HTTP overriding and to prevent that additional security to validate the client’s authentication would required.
Parameter and URL Standards

When defining parameters and urls there should be a specific standard followed in order to avoid confusions when consuming the API. There are couple of naming standard are available such as below;

1. Camel Case
According this standard the first letter will be lower-case and each first letter of the word of the parameter would begin with a capital letter without any spaces among them.
Parameter : systemVersionId = ‘1234’
2. Snake Case
Each word in the parameter or the url would be separated with an underscore character.
Parameter : system_version_id = ‘1234’
URL : GET /v1/course_enrollments/12
However when the underscore is used in url’s some web-crawlers would not be able to rank the url properly.
3. Spinal Case
Word separation of parameter and the url would be done based on a hyphen character according to this standard.
Parameter : system-version-id =’1234’
URL : GET /v1/course-enrollments/12
The combinations of the above standard are not encouraged to used within APIs where in the API design it has to be stick to a specific standard throughout.
Support for Log Aggregation
In the APIs it is important to support for log aggregation where each API should have a specific identifier which is unique for each transaction which is also known as the correlation-id. There are several log-aggregation tools available such as;
Unmanaged / Self-deployable Services
- Splunk
- Logstash
- Apache Flume
- Scribe
- Graylog2
- Chukwa
Managed Services
- Retrace
- PaperTrail
- LogEntries
- Loggly
Will be discussing detailed comparison of the tools in another blog post (Log Aggregation).
Securing API

Securing the API is much critical since unsecured APIs would get exposed for unnecessary execution of APIs and expose of information over unauthorized parties. There are several methods available in securing APIs such as;
- Basic Authentication
- API Keys
- SAML Based Authentication (Security Assertion Markup Language)
- OAuth 2.0
- JWT (Jason Web Token)
Will be discussing this broader subject in another blog post. (Securing the API)
Documentation

Documenting the API is absolutely important since everything described above in this blog is presented to the end-user over the documentation. There are many tools available to present the API content to end users. Based on the licensing and organization requirement any of following could be used.
- Swagger
- Spectacle
- ReDoc
- OpenAPI
Conclusion
According to the requirement and the standards of the organization and product a unique set of practices has to be selected which is used across the entire API eco-system consistently.
~ Thisara
