Controlling Throughput on API

The infrastructure that the API services are deployed has a cost factor coined with it and relative to resource consumption on infrastructure such as CPU, Memory, Disk Space, Bandwidth etc. the cost factor of infrastructure would also increase.
A high volume of calls on API services at at given time would increase server resource consumption and if auto-scaling is enabled over a cloud infrastructure, it will spin-up more instances which will increase the cost of infrastructure. If the load is due to an unauthorized intrusion it would be a chaos. Thus, use of a limited rate-for-service calls during a specific time block is important in API communication.
Limiting of API service consumption is generally applicable for concurrent calls made by a single consumer who is identifiable with a single API identity. The thresholds of API throttling has to be set based on the predicted consumption of the API during specific time periods of the day (14 00 – 15 00 / 18 00 – 22 00) or fixed time boxes (Daily / Hourly).
API Quota

A general method of limiting usage of API resource is to allocate a pre-configured static or dynamic quota for a consumer. Fundamentally the quota could be constructed based on following factors.
- Consumer : The consumer could be a user (identify with a userID), application (identify with an applicationID) or a device (identifiable with an IP). And there could be other types of consumers who are capable of identify with a unique identity.
- Duration : There should be a specific configurable period where the allocated quota is active and upon expiration of quota active period, it has to be reset.
- API Unit : The controllable units within the API has to be identified such as functions, group of services, resources etc.
For example :-

figure 1.0 : Sera (Consumer) would have quota 10000 calls per month (Duration) on entire API (API Unit)

figure 2.0 : Jenny (Consumer) would have quota 5000 calls per month (Duration) on a specific API service or per API service (API Unit)

figure 3.0 : 192.168.1.5 (Consumer) would have quota 1000 calls per day (Duration) on entire API (API Unit)
The structure of defining the quota would be based on the requirement and the estimated cost of execution. Thus, cost of infrastructure and the sensitivity of data would be some primary factors to be considered while constructing the structure of the quota allocation formula.
There are static and dynamic quota allocation formulas are available where many researches are being conducted on building AI and ML based dynamic quota allocation formulas. The main advantage of dynamic quota is to utilize the API resources to the maximum. Even though the quota is expired of a particular consumer the server resources could be running idle and the quota could be dynamically increase to consume the idle server resources until a quota available consumer returns.
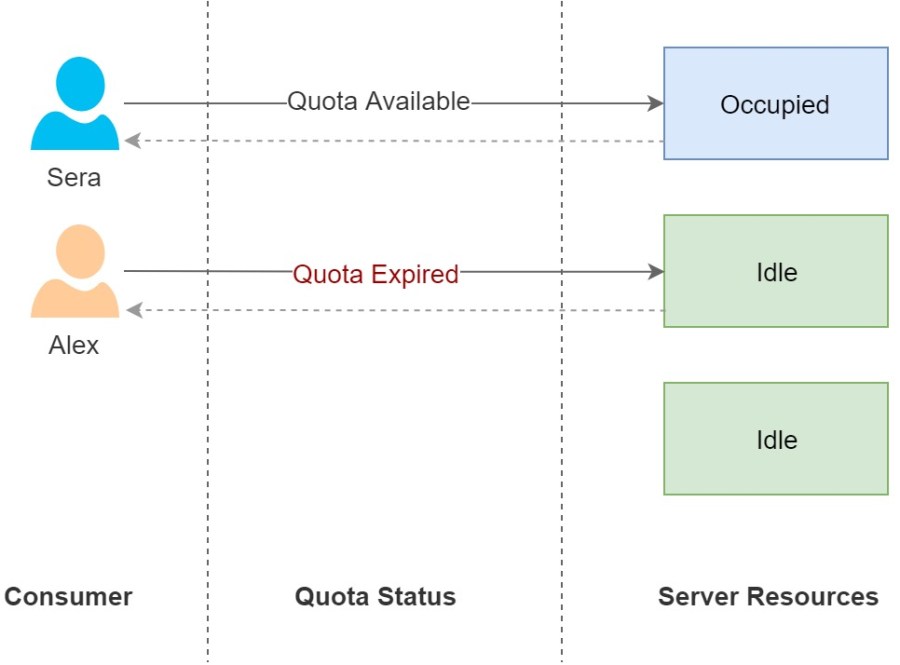
figure 4.0 : Dynamic Quota : Request would be served if the server resources are idle although quota expired.
API Burst

This is another aspect of quota and this defines the the maximum number of concurrent calls that an API or a unit of API could accept at a specific time frame and this is also known as the maximum concurrency of an API. In addition, this is a security measure since this restrict the denial of service attacks from intruders.
Further defining the maximum concurrency limit in a dynamic approach is also considered under same topic where although the upper limit of concurrent calls are already reached to the maximum, the API will allow more concurrent calls if the API has bandwidth or server resources are idle. The maximum concurrency of an API is also known as the API Peak.

figure 5.0 : Instead of getting a single request from a user, during the lifetime of the API it would be getting 50 request during a period of a second. Which is known as a burst and the API should have pre-defined peaks and a strategy to handle the burst without impacting API services.
API Throttling

A way of managing the defined quota and burst against an API consumer is usually know as throttling there are different levels that throttling could be applied such as;.
- IP based Throttling
- Allow API access with throttling only to a set of white-listed IP addresses where per IP address throttling would be configured. This is most suitable for API systems built for inter-system communication where only a fixed set of IP addresses are involved in the communication.
- Function based Throttling
- Once each distinct functions provided by the API are being listed, throttling could be configured for each unique function. The configuration would be based on the execution complexity and the cost where if a particular function consume more computation power at back-end to generate the result the API burst (concurrent calls) of the function would be a smaller number.
- User based Throttling
- Per user API throttling limits would be defined and one advantage would be that for users who are not subscribed under a commercial agreement with the API would have much lesser quota and burst. The subscribed users would have different options available at different pricing.
- Resource based Throttling
- Throttling of data returned by an API is known as resource based throttling. If a query executed at back-end for an API service, returned a large data volume the result could be throttled using query languages. In most scenarios this would either return the latest set of records (if only latest information is needed) or paged set of data (if all data result is required).
- Tier level Throttling
- Within the API throttling would be implemented in different tires of the application such as.
- Database level
- The throttling algorithm would be implemented either at database level or data-access level where the quantity of data returned or number of data requests would be throttled.
- Service level
- Throttling at service level would be usually limiting the number of calls or concurrent calls to the service.
- Database level
- Within the API throttling would be implemented in different tires of the application such as.
- Hybrid Throttling
- A hybrid formula could be used based on the business requirement of the API consumers which would be identified as a hybrid approach.
Methods of implementing throttling

The best approach to verify the quota would be over interceptors where pre-filters will verify remaining quota and decide which action to be executed to proceed with the request. And each execution would be handled by a thread which is fetched from a pre-instantiated thread pool instead of instantiating new thread upon each request.
The API Burst algorithm could be implemented on the throttling implementation layer or on bottom level of the program such as at service level, data access level or database level. However this would differ based on the way throttling is handled such as, it could declines all the requests after throttling limit is reached, reduce bandwidth or switch to asynchronous processing as decided by the rate limiting algorithm used.
Decline API Calls
The simple mechanism would be to decline the requests upon expiration of quota with 403 HTTP error code to denote that the allocated quota for this current time unit has been expired or burst with 429 HTTP error to denote too many requests. And the consumer would aware when to retry on the same based on the time unit shared with the consumer along with the respective quota or with the information provided on the HTTP response header such as;.
On AWS MWS;
Control bandwidth
Once the quota is exceeded the bandwidth could be reduced for a specific user or application. This would limit the number of calls to the service and if there are more service calls received than expected the API would return 429 Error code to denote ‘Too Many Requests’.
Synchronous vs Asynchronous processing
Another approach is to switch to asynchronous processing when there are too many requests if loss of service calls due to throttling is not acceptable. And it is important to process the queued data in another process pipeline without affecting the synchronous work-flow. A request queue could be implemented to queue the messages and following products could be leveraged;
- Use of RabbitMQ
- One option would be to leverage a RabbitMQ message queue where a listener would pull messages from the queue and process them asynchronously.
- Use of SQS (AWS – Simple Queue Service)
- If the services are on AWS the SQS would be an effective solution for the queuing purpose.
API Rate-limiting
The rate of executing the API requests are being controlled by the rate limit and there are many rate limiting algorithms are available in use which are applicable based on the requirement.
Rate-limit Algorithms

Token Bucket
Per user unique token would be delivered with a predefined number of requests which could be served during a specific and predefined time-frame.
There are three operations to be performed upon a request arrival such as;
1. Fetch and validate token
2. (Quota Available) Process request with token bucket update
3. (Quota Not Available) Deny request
The overall sequence is being illustrated in figure 6.0 sequence diagram.

figure 6.0
Describing the functionality of the ‘Token Bucket’ in details;
Assume user ‘alex001’ is invoking a specific API service and the user is given 5 requests per minute as the quota. At a given instance the state of API consumption would be depicted on figure 7.0 where the last API call has made at 08:10:01.
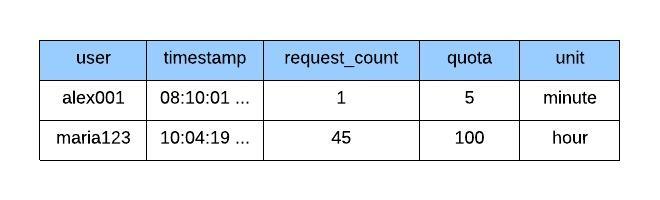
figure 7.0
The user is making the second API call at 08:10:20 and the Token Bucket would verify the timestamp and realized that the request is making during the same minute. And it will instruct to process the request once after update the timestamp and request_count. Data will get updated as in Figure 8.0.

figure 8.0
Once a burst of requests arrives during following timestamps such as 08:10:35, 08:10:36, 08:10:37, 08:10:38, 08:10:39 with 5 requests, the quota and the request_count would get equal once after processing the request made at 08:10:37 and the rest of requests at 38th and 39th second would get discarded. Refer the data updates in figure 9.0.
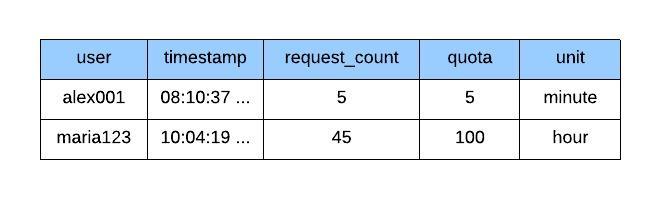
figure 9.0
When a new request is made during 08:11:20, the request count would get reset as per figure 10.0 and the user would be able to invoke the API again.

figure 10.0
Leaky Bucket
The main difference in this algorithm is that the requests would get processed in a fixed rate even though multiple API calls are being called on the API as a burst. A fixed number of requests will be served and the calls out of the quota would get declined. The order of processing would be FIFO (First In First Out).
As per the following example depicted in figure 11.0 the API would get accept only 4 requests within the bucket at any given time. And they will get processed in a static rate which is 1 request per 5 seconds.
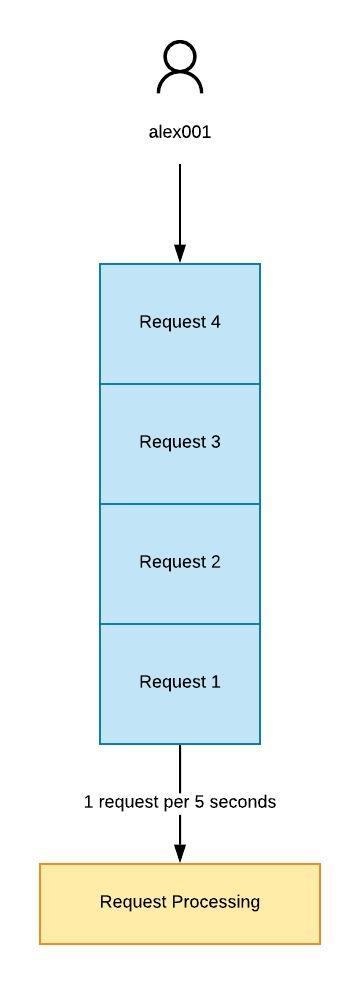
figure 11.0
The sequence of usual processing of Leaky Bucket is depicted on figure 12.0 sequence diagram;

figure 12.0
This algorithm is most useful for asynchronous processing where the response of processing would get notified to the consumer via a sub-pub service if required. One of the main advantage is that this would avoid burst of request which could be a DOS (Denial of Service) or DDOS (Distributed Denial of Service).
Fixed Window Counter
This is a memory efficient approach of limiting rate where for each request a counter will be maintained until the allocated quota is getting expired.
For example if the quota is defined as 5 requests per minute a counter would be defined as below in a key-value pair as in figure 13.0;
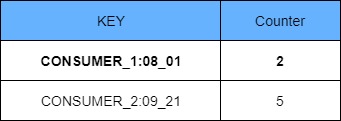
figure 13.0
AS per figure 14.0, once the request count reached 5 for CONSUMER_1 during the minute of 08:01, all the subsequent requests would be declined.

figure 14.0
When the request made during the subsequent minute the counter would get reset and the request beings to serve by the API as in figure 15.0.

figure 15.0
One problem with this approach is that this will not behave properly in the event of an API burst.

figure 16.0
According to the above example depicted in figure 16. 0, if an API burst received on 08 01 55th second for 15 requests; 5 requests will be processed during last 5 seconds of the window and renaming requests will spill over to the next window. Since the quota is 5, 5 requests will be processed during first part of the window. When consider 5 seconds backward and forward from the window boundary the API is processed 10 requests during 10 seconds (60 / min) which is violating the defined rate.
Sliding Logs
In this approach instead of limiting rate of fixed windows, the rate is calculated over real-time. Unlike in Fixed Window Counter, each request is being logged with their received time-stamp in a memory db.
An example is shown below for CONSUMER_1.

figure 17.0
As per the example in figure 17.0, time-stamp of requests of each user is maintained and the rate is calculated on the fly as below;

figure 18.0
As per time line illustrated in figure 18.0, the A, B and C calls are executed during three different time-boxes. The time-box is defined as 1 hour in this example.
A – When the request is made during 08 20, the call count from 07 20 to 08 20 is taken and compared with the number of maximum calls allowed during the time-box.
BEGIN
IF total-allowed-during-time-box < total-call-count-during-last-time-box
Allow processing of request
ELSE
Deny request processing
END
The detailed sequence of actions in order to control throttling is elaborated in figure 19.0 sequence diagram.

figure 19.0
The main issue with this approach is that the each call during the last time-box has to be maintained either in a hash-table or external caching server and when the number of calls are getting increased the space consumption would get increased and it will increase the cost of deployment.
Sliding Log Window
This is quite similar to the Sliding Logs and the only difference is that the duplicating timestamps are being grouped in to a single record to make it more memory efficient.

figure 20.0
As illustrated in the figure 20.0 data structure, requests arrived during the same time stamp are being grouped together to save the storage space.
Processing of the request would be identical to the sliding log algorithm illustrated above.
Throttling in Distributed Systems

While executing the throttling within a distributed environment there would be data inconsistency issues due to different data sources or data persistent paths used. There are several models expressed below to compare and contrast the trade-offs.
Remote DB Sync Service with Eventual Consistency
As per figure 21.0 when the system is distributed there would be obvious sync of data required in order to provide a consistent outcome for users.
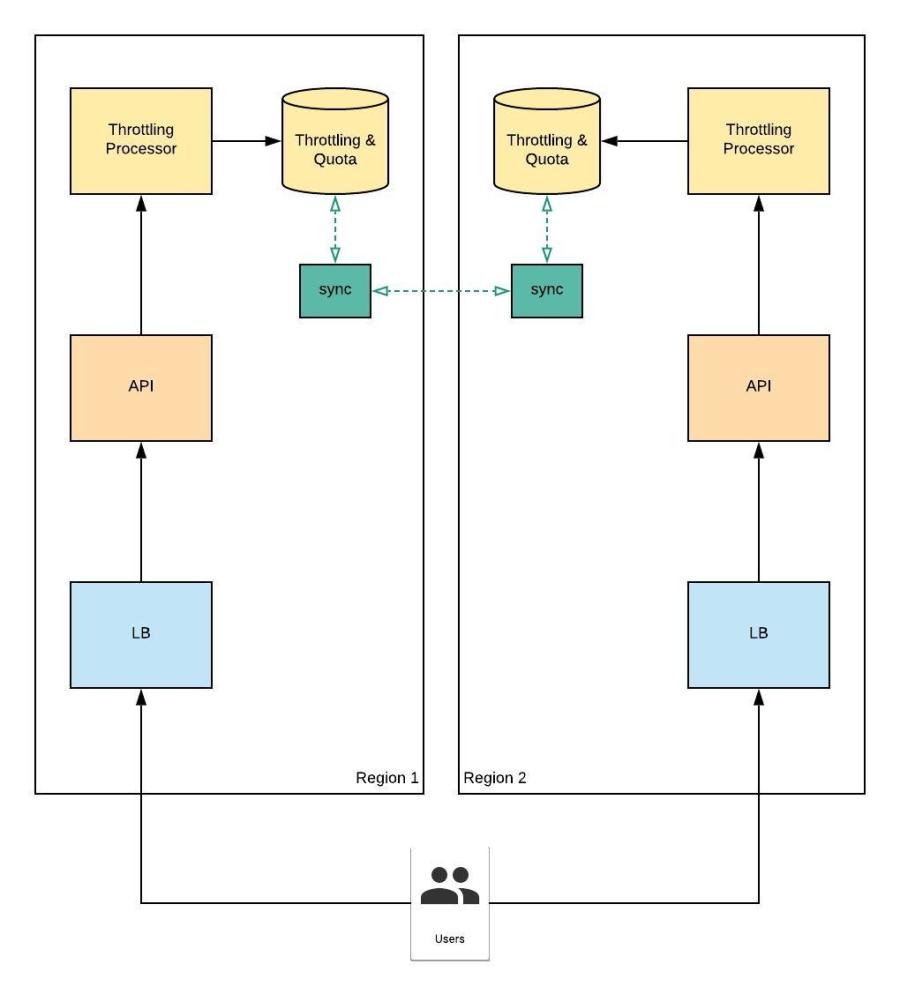 Figure 21.0
Figure 21.0
There would be an added latency in data synchronization due to network and IO (Input – Output system) delays. Due to the delays, two databases would be out-of sync for a while until the synchronization process is fully completed over each write operation.
For example;
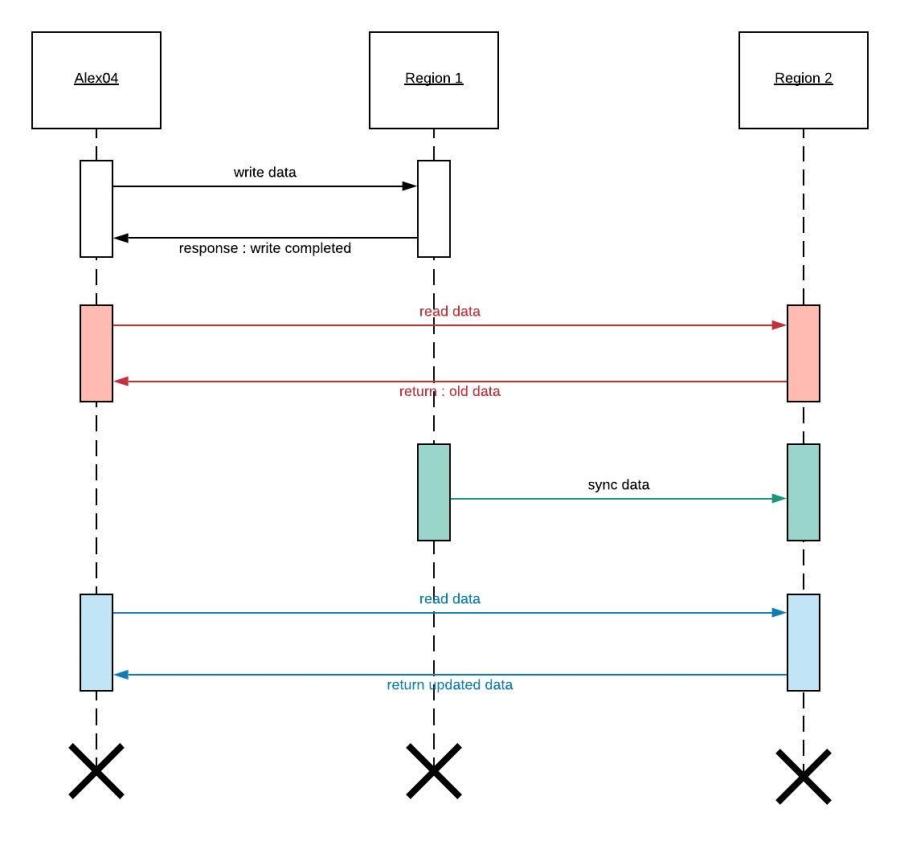
Figure 22.0
As per the Figure 22.0, when there is a delay in syncing data between remote data bases and in case user ‘alex04’ attempt accessing data before data sync, old data will be returned which will violate the database consistency principle. This behavior is expected since Eventual Consistency model is used.
Pro : User will get quick response once after data is written to DB
Con : Data inconsistency due to Eventual Consistency
Applicable : This is applicable when there are high writes and low (concurrent) reads
Remote DB Sync Service with Sticky Sessions

Figure 23.0
One other option is the use of sticky sessions and the advantage is that the db-sync service delay would have much reduced impact since the user ‘alex04’ is interacting with a fixed region based on the SSO session that is initiated with the server.
However this is debatable since the purpose of distribution is to avoid single point of failure with distributing the load among replicas equally. As per the above example in-case the region 1 services timed-out user will experience additional latency while the session is re-establishing and may be data inconsistencies if the data sync services are not executed completely.
Pro : Reduced chances of data inconsistency (if not experienced time-out or service fail)
Con : Load is not equally distributed and sticky session management
Applicable : Data consistency is preferred over equal load distribution
Remote DB Sync Service with Strict Consistency
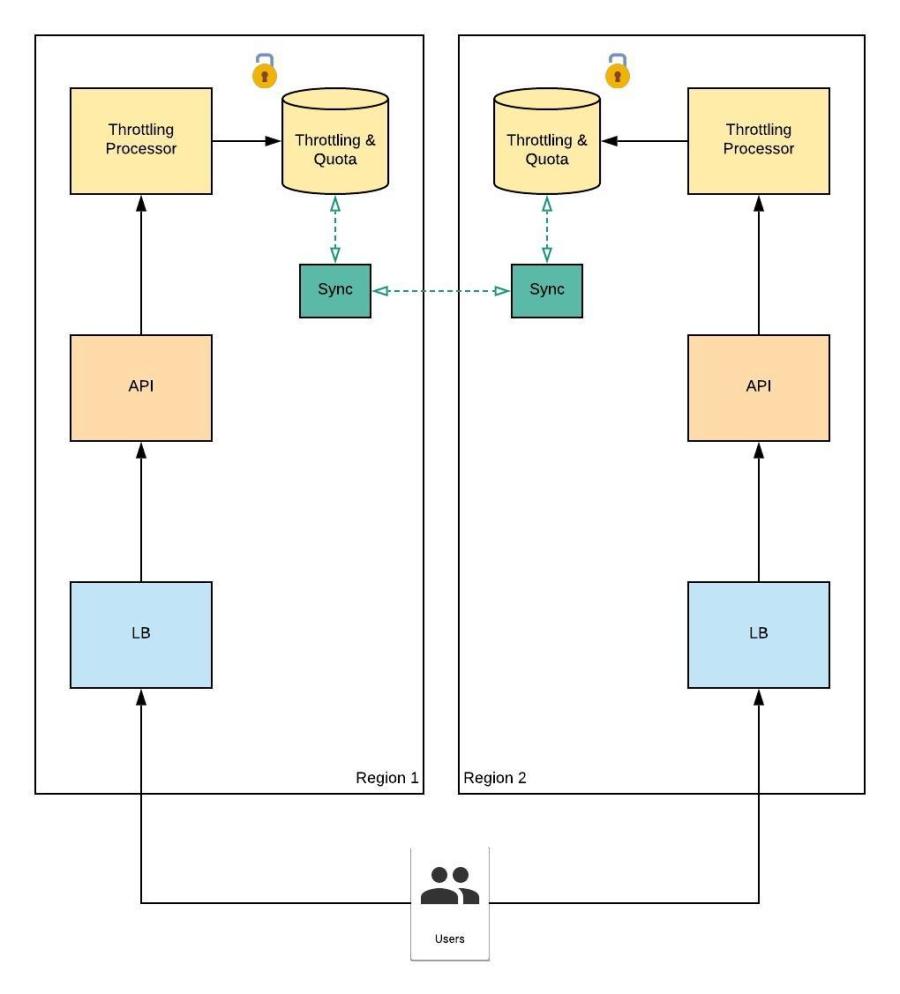
Figure 24.0
A solution for the issues with the Eventual Consistency model is to adapt in to a Strict Consistency model with data locking mechanism.

Figure 25.0
As per the example depicted in Figure 25.0, when the user initiates a data write operation a lock will be acquired on the remote db and if the user ‘alex04’ initiate a read call it will put on waiting state until the lock is released after the data sync. User will not experience data inconsistency issues although there will be an additional latency added in reading data.
Pro : No data inconsistency
Con : Additional latency could be experienced by the user
Applicable : Data consistency in reading is critical
Local Cached – Remote DB Sync Service with Eventual Consistency
 Figure 26.0
Figure 26.0
This model would be ideal if the Eventual Consistency is preferred and read performance is vital. Instead of calling a remote database over network IO, all data or frequently accessed data (LRU (Least Recently Used) Cache) would get accessed from in-memory database. A data sync service would be required to maintain data in sync between remote databases.
Pro : Read – Write performance is enhanced due to reduced network calls
Con : Could experience data inconsistency due to Eventual Consistency model
Applicable : To increase performance of the model depicted in figure 21.0
Load Balanced Centralized DB Sync Service
 Figure 27.0
Figure 27.0
When the number of regions are increased it will be a hassle maintaining multiple data bases and keeping them in sync. This model would interact with a load balanced centralized data storage accessible for all the regions. However local cache or regional databases could be used based on the requirement and this centralized data storage would act as a mirror and data backup store which handles data restoration in case of region specific data services are failed.
Pro : Reduced chances to data losses
Con : Could be added latency due to remote region data base service
Applicable : When the application replicated over many regions
Conclusion
Based on the business and the technical requirement of the application the best applicable framework has to be decided and it would be a framework built with collaboration of the models elaborated above.
References:
helpx.adobe.com/coldfusion/api-manager/throttling-and-rate-limiting.html
nordicapis.com/everything-you-need-to-know-about-api-rate-limiting
youtube.com/watch?v=g_3e_bNU2e0
dzone.com/articles/api-throttling-made-easy
docs.wso2.com/display/AM200/Setting+Throttling+Limits
apifriends.com/api-management/api-quota
docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-request-throttling.html
petefreitag.com/item/853.cfm
youtube.com/watch?v=efcTdYxY_90
youtube.com/watch?v=Q53eR7mFsRo
linkedin.com/pulse/redis-vs-rabbitmq-message-broker-vishnu-kiran-k-v
leakybucket-javacode.blogspot.com

Reblogged this on Idea to geek.
LikeLike