Git is a version controlling system introduced by Linux development community and according to the history Git was built due to breaking down of the Linux partnership with BitKeeper (Subversion) in 2005.
An Australian engineer Andrew Tridgell who invented Samba file server was engaged in reverse engineering the BitKeeper System which violated the license agreement existed according to Larry McVoy who was the CEO of BitKeeper.
Linus Torvalds who is the principal developer of the Linux community made this as an opportunity to build a new hassle free version controlling system with resolving the frustration that they already experienced with BitKeeper. The following were the few design objectives outlined to be achieved with Git.
- A corruption free, safe-guarded, high speed and distributed system.
- Less time consuming for system patches (should be less than 3 seconds).
- Centralized and Distributed repository.
- Efficient non-linear development support.
Git Architecture
The main work-flow from developing a code on a PC to push it on to a remote git server could be depicted on the below sequence diagram.
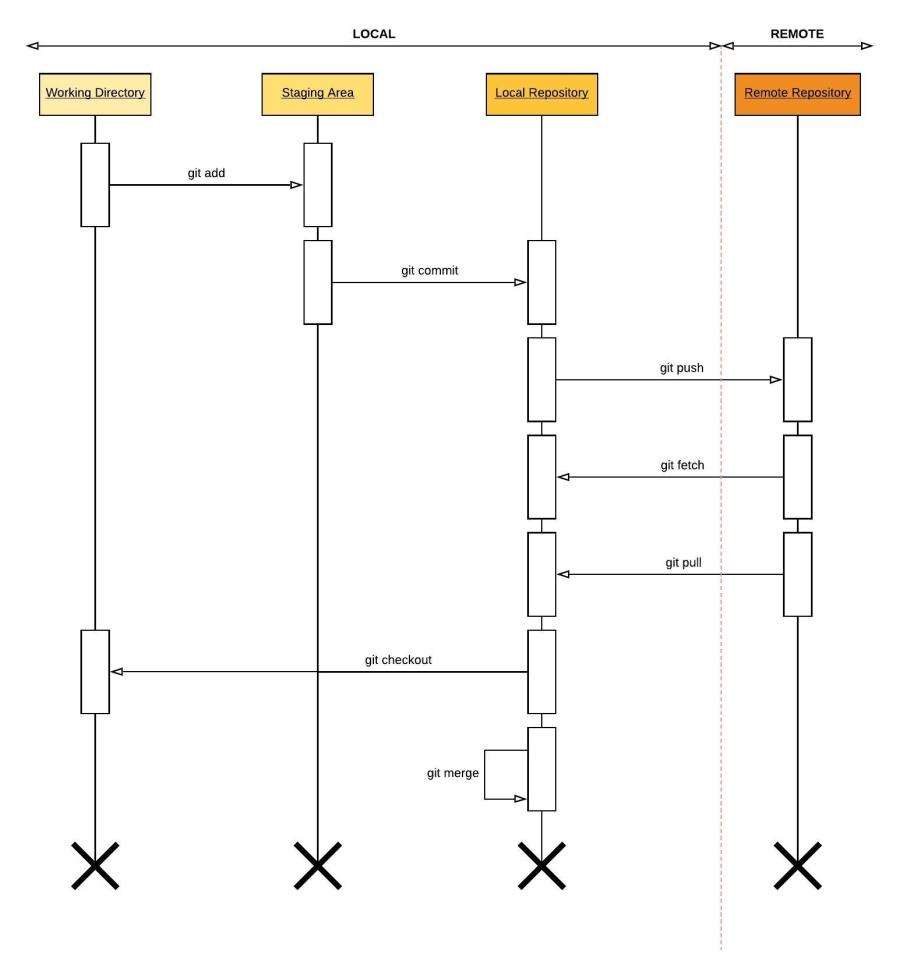
Figure 1.0 – Git transaction work-flow
Working Directory
Files which are created or modified on the local computer which are not considered to be added on to git are residing within the working directory.
Staging Area
Files which are ready for commit will be added on to staging area.
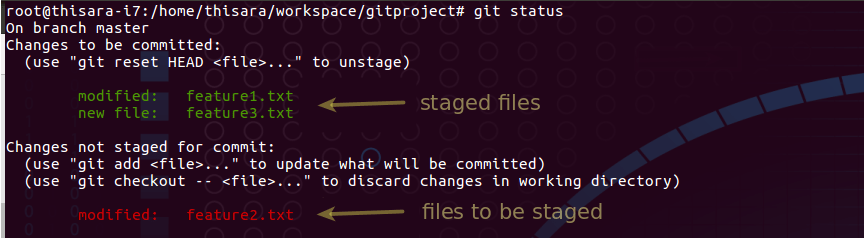
Figure 2.0 – staging area snapshot
According to figure 2.0 which reflects staging area, feature1.txt and feature2.txt are added on to staging which are ready to commit and feature2.txt is still within the working directory.
Local Repository
This is the local Git repository of the developer. Once issue commit on a specific branch, staged files and directories will be committed on to the local-repository.
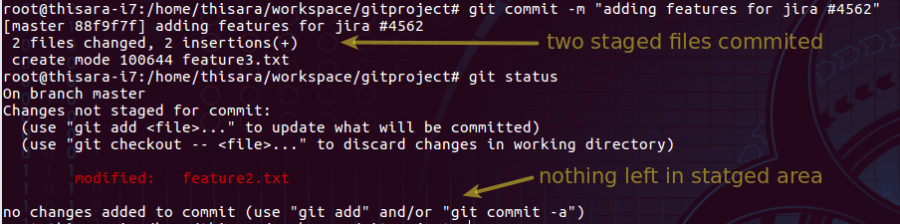
Figure 3.0 – commit staged changed on local repository
Two files which were ready to commit as per figure 2.0 are being committed on to the local repository. As per figure 3.0, the non-staged file remain without any change.
Git has the feature of checking-out specific commit and option of starting a branch out of it. The Git command git checkout <commit hash>; will checkout the state of a commit hash, and even modifications on the files could be conducted without impacting the original files in the local repository. If new branch is not created with the changes made changes will get destroyed once switch on to another branch.
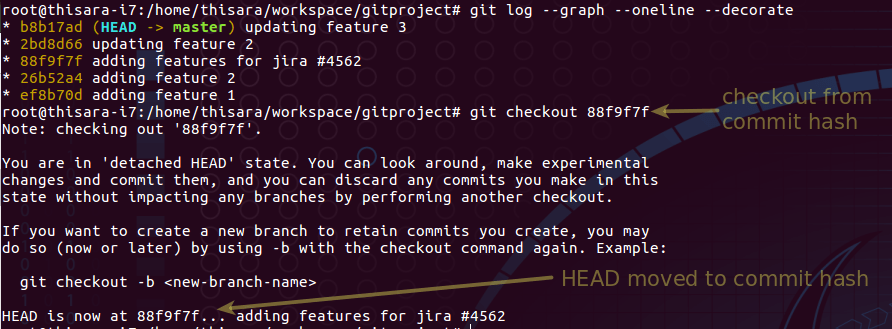
Figure 4.0 – Checkout from commit hash
As per figure 4.0, the HEAD is on a commit hash where the commands will execute on.
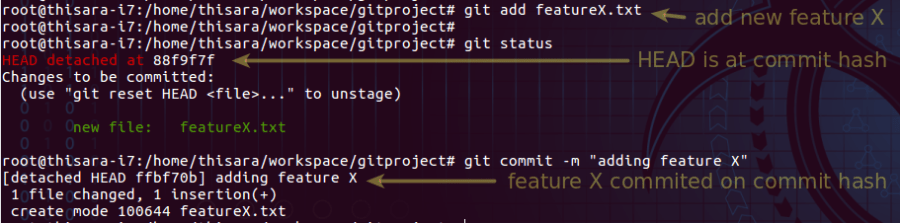
Figure 5.0 – Modifications on a commit hash
Referred to figure 5.0; let’s create a new file and commit it on to the current branch and this change will retain until a new branch is created with the changes.
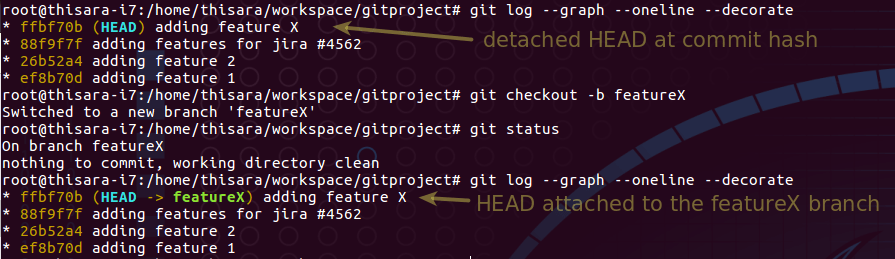
Figure 6.0 – create branch from the commit hash

Figure 6.1 – new branch is referencing on featureX branch
Branch featureX is created with the changes made over the detached HEAD at commit hash as per figure – 6.1.


Figure 7.0 – Diff featureX branch with parent branch
The parent branch could be continued separately or deleted if not required. Let’s delete the existing master branch and rename the new featureX as the master branch.
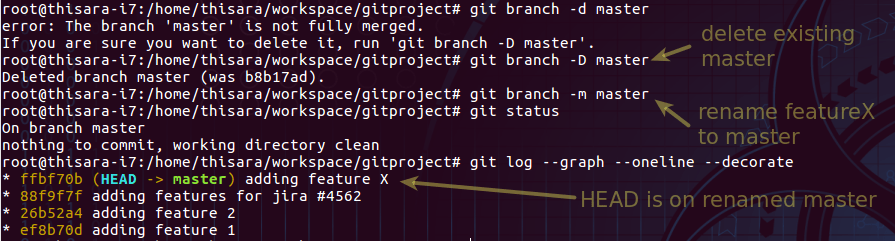
Figure 8.0 – remove the old branch and rename new branch to continue
Force delete the branch with ‘D’ argument to force, and in the event of that everything should be merged prior to delete use argument ‘d’.
Git Objects
Git is a giant object graph where the objects are being linked with pointers. There are three main objects in Git such as;
Commit – A pointer to a tree of changes on files which is tracked along with some meta data such as the author, comment, change type etc. Branches and Tags are references which always point to a Commit object.
Tree – A pointer or collection of pointers linking to a Blob or to another Tree of changes.
Blob – Binary Large OBject; The actual file resides on the disk which is instantiated.
 Figure 9.0 – object relationship in Git – (Arrows depict pointer directions.)
Figure 9.0 – object relationship in Git – (Arrows depict pointer directions.)
As per figure 9.0; changes on branch will be carried out by a particular Commit object via the HEAD pointer which will point on a particular branch at a time. Each commit will be pointing to a Tree object and it will be aware of the blob object(s) which should get change based on the request.
Any commit object holds the complete snapshot of the entire repository and this is one of the main difference compare to SVN. Each commit in Git is uniquely identifiable with 40 characters long SHA1 hash. Unlike in SVN, git does not maintain copies of entire repositories and the state of the repository is maintained as a Directed Acyclic Graph.
Directed Acyclic Graph (DAG)
This is a type of graph where it is impossible to traverse backward to the same node again and it ensures that the graph grows only in one direction. And the objects (vertices) in DAG are not experiencing any circular behaviour where the edges will not reference to a previous vertex in the object graph.

Figure 10.0 – Directed Acyclic Graph
Git objects are tracked and identified with 40 characters long SHA1 hash value which is a unique number. When the same SHA1 is generated for identical content created by two people which is also known as a collision, two pointers will be created for the same content since content duplication is fully avoided in Git.
Git objects are encrypted and the information that holds could be retrieved only via git cat-file command. Let’s find details of each object type.
Commit
Upon each commit all the changes are being grouped on to a single commit object. All the commits will be executed over the HEAD pointer which points to a specific branch on the repository. A commit object holds following information.
Tree – Pointer to a Tree object; which is a pointer to a file on disk or another tree.
Parent – The parent commit for this commit (if this is not the first commit on the repo)
Author – The username of the person who wrote the code.
Committer – The username of the person who committed the code behalf of author.
Message – The commit message added on the commit.

Figure 11.0 – Details of a Commit object
Tree
Pointers which are linked to files on disk or on to other Tree object is known as a Tree object. File operations will be performed via a Tree object and in the figure 12.0 the tree object on hash a191c4 is referring to the blob objects on hash 79dab9, 404e37 and 11257b.

Figure 12.0 – Details of a Tree object
Blob
The actual file on the disk will be displayed as a blob object. As per figure 13.0 the content which is available on the blob object 79dab9 is displayed.

Figure 13.0 – Details of a Blob object
How Git DAG Created?
Let’s follow the following scenario to depict how the object graph grows along with the commits in Git.
Creating index.jsp file on a new repository and commit it on the master branch;
- git init
- Initialize empty git project.
- vi index.jsp
- Add file content : This is the index file.
- git add index.jsp
- Blob object got created : 3a7b58 – (figure 14.0)

Figure 14.0 – Blob created for the file index.jsp
- git commit -m “adding new index file” – (figure 15.0)
- Tree object got created : b1533f
- Commit object got create : 8302d5
- Tree object is referring on 3a7b58 blob object


Figure 15.0 – Committing index.jsp on master branch
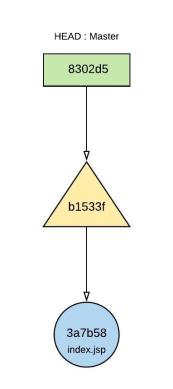
 Figure 16.0 – Pointer directions on Object reference hierarchy
Figure 16.0 – Pointer directions on Object reference hierarchy
Relationship between objects with their pointer directions are depicted in figure 16.0.
Updating the index.jsp file and commit on the master branch;
- vi index.jsp
- Update file and add content : This is the first update
- git add index.jsp
- New blob object created : cd2d8f
- git commit -m “first update of index file” – (figure 17.0)
- New Tree object created : 73d7bb
- New Commit object created : 0b9bda
- New Tree object referencing to cd2d8f blob object


Figure 17.0 – Update commit index.jsp on master branch
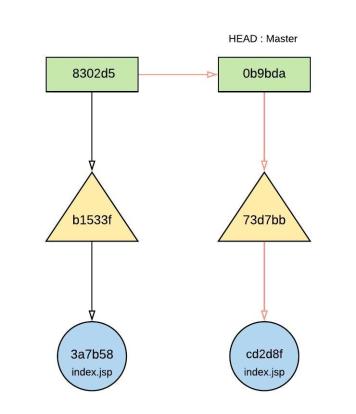
 Figure 18.0 – object relationship after updating index.jsp
Figure 18.0 – object relationship after updating index.jsp
Adding a new home.jsp file and commit on the master branch;
- vi home.jsp
- Add file content : This is the home file.
- git add home.jsp
- New blob object created : 47440c
- git commit -m “adding new home file” – (figure 19.0)
- New Tree object created : 8c7a7a
- New Commit object created : 7c10f2
- New Tree object referencing to cd2d8f and 47440c blob objects


Figure 19.0 – Committing home.jsp on master branch
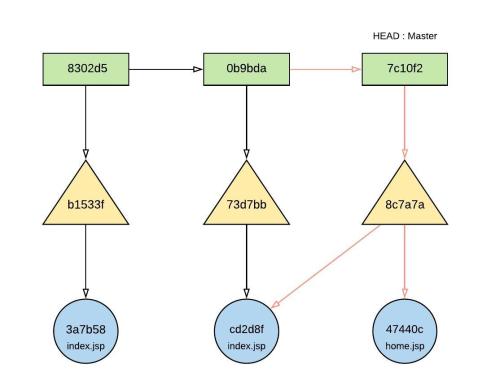 Figure 20.0 – object relationship after creating home.jsp
Figure 20.0 – object relationship after creating home.jsp
Creating a new branch ‘feature’ and commit new feature.jsp on the branch;
- git branch feature
- New ‘feature’ branch is created and in .git/refs/head/develop directory it was pointing to last commit object : 7c10f2
- vi feature.jsp
- Add file content : This is the first feature.
- git add feature.jsp
- New blob object created : 9e0820
- git commit -m “adding first feature” – (figure 21.0)
- New Tree object created : e445b9
- New Commit object created : 1cba14
- New Tree object referencing on 47440c, cd2d8f and 9e0820


Figure 21.0 – Create new branch ‘feature’ and committing feature.jsp
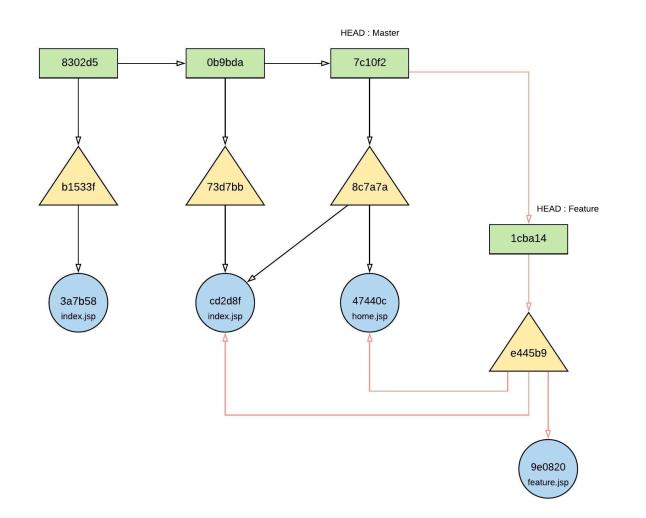 Figure 22.0 – object relationship after adding new branch with feature.jsp
Figure 22.0 – object relationship after adding new branch with feature.jsp
Let’s create another branch ‘develop’ and commit test.jsp on the branch;


Figure 23.0 – create develop branch and committing test.jsp
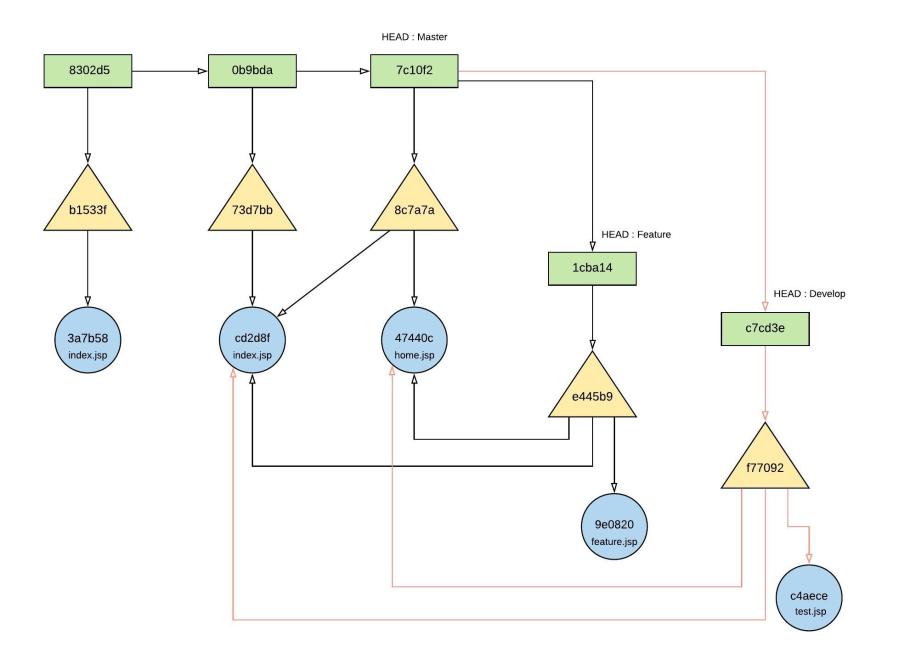 Figure 24.0 – object relationship with develop branch and committed test.jsp
Figure 24.0 – object relationship with develop branch and committed test.jsp
Merging feature branch changed on the master branch;
- git merge feature (on master branch)
- Since there are no any changes on the master branch after branching, master branch will be referencing to the feature branch Commit hash : 1cha14 as per fast-forward merging strategy.
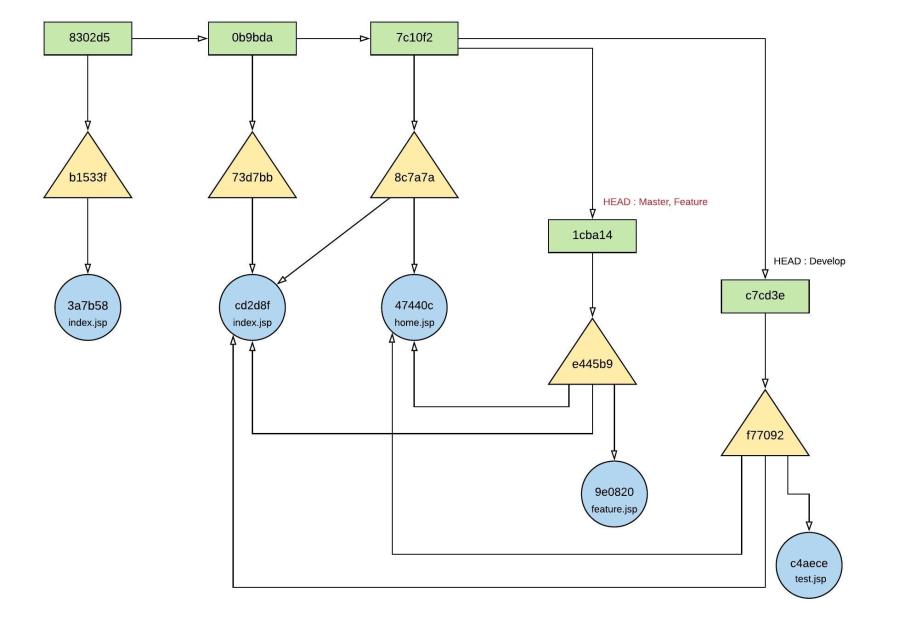 Figure 25.0 – object relationship after merge feature branch on master branch
Figure 25.0 – object relationship after merge feature branch on master branch
Merging develop branch on the master branch;
- git merge develop (on master branch as in figure 26.0)
- New commit object created by recursive merge strategy, since there are changes on master branch after creating develop branch due to feature branch. Commit object : d674d7.
- New Tree object created : 61a656
- New Tree object referencing on : c4aece, 9e0802, 47440c and cd2d8f
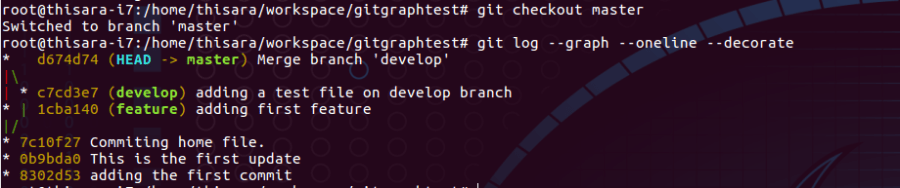


Figure 26.0 – merging develop branch on master branch
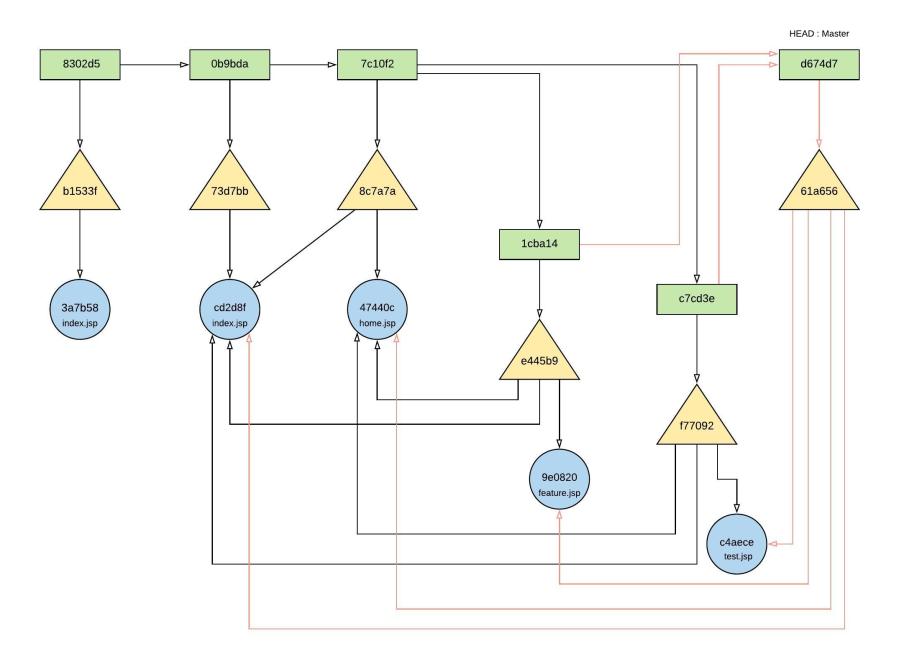
Figure 27.0 – object relationship after merge develop on master branch
This is how Git maintains full snapshot on each commit using pointers and the graph would expand tremendously as commits are added on the repository.
Contents In .git Folder
.git/objects
Each commit on the repo is identified by 40 characters long hash and they are groped into folders by the first two numbers and the rest of the object hash is stored in each respective folder. Objects would be in type of commit, tree or blob.

Figure – 28.0 – contents of git objects folder
There are two additional folders such as pack and info where pack used to maintain compressed objects and info hold the information about packs. Objects which are visible are the ones which are getting used frequently and as soon as git gc invokes for garbage collection, all the objects will get compressed.


Figure – 29.0 – compress git objects
As per the figure 29.0, once after garbage collected all the objects are disappeared and there are new two files created in pack with .pack and .idx extension. Data related to object are maintained in .pack and table of content (or indexes) are maintained in .idx file.
Let’s get a hashdump of the .idx file to verify how the commit object ‘b69421ae695a8883341dedea3ddb0fb45f139548’ is listed as in figure 30.0.

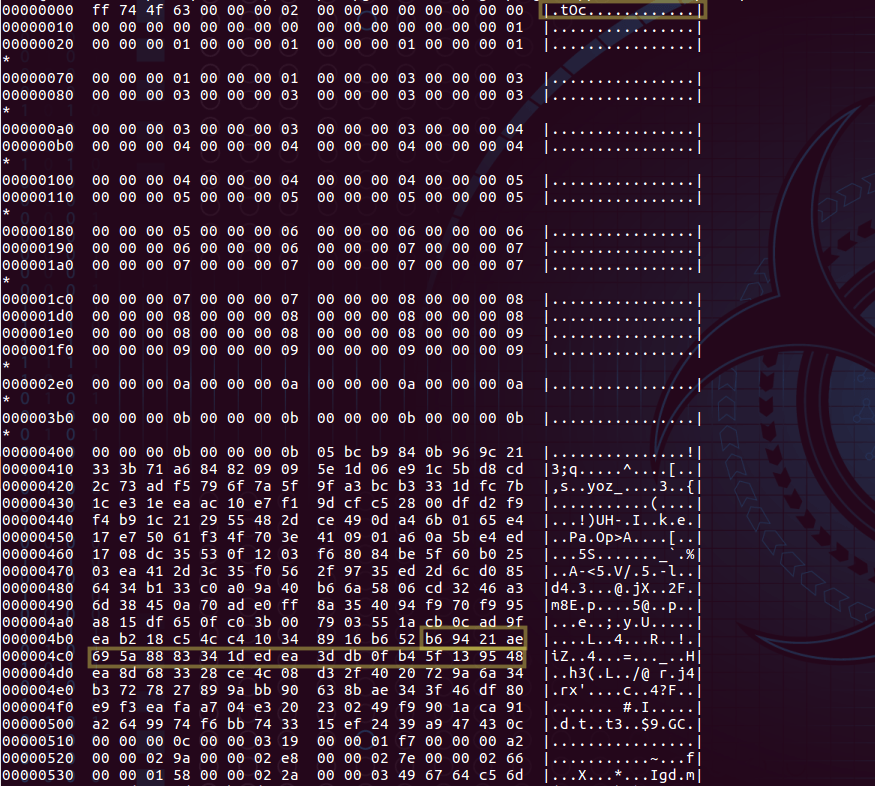
Figure – 30.0 – content arrangement in .idx file
Git does the object compression to optimize the space consumption where as per figure 31.0 compressed read-only file of all the objects consume 8.0K where as a single object with empty content consume 8.0K as per figure 32.0.


Figure 31.0 – file size of .pack and .idx files

Figure – 32.0 – file size of a single commit object with no file content
.git/config
Following configurations are mainly held within this file;
- Git native configurations
- Remote origin URL
- Branches that is check-out on local with their merge path

Figure – 33.0 – git config file snapshot
.git/refs
All the branches and tags created in the repository are listed on the refs configuration folder as per figure 34.0.

Figure – 34.0 – contents of git refs folder

Figure – 35.0 – the last hash of HEAD pointer of master branch
As per figure 35.0 the commit hash referenced by a particular branch is the latest commit pointer of that particular branch.
.git/HEAD
This is the pointer which maintains where the HEAD is pointing within the repository at a given time.

Figure – 36.0 – content of HEAD file which points to a branch at a time
According to the figure 36.0 the HEAD is pointing on master branch which is the last commit of this repository as displayed on the figure 35.0.
.git/hooks
Configurations to be executed upon events are available here and more details available under the Git Hooks topic below.
.git/COMMIT_EDITMSG

Figure – 37.0 – last commit message within the repo
This holds the latest commit message made on the repository as per the figure 37.0 the latest commit message was “Dockerize”.
Git Branches and Forks
Branch
In Git, branch names are created under .git/refs/head/<branch-name> and the HEAD of the branch will be referencing to a specific Commit hash. Objects are not coupled to a branch and branches are referenced on the giant Git object graph.
Master is know as the Canonical mainline branch where there are no any default branches defined at the time or creating a repository, Git will be creating master.
Fork
Once someone is intended to use a particular repository in order to develop it as a separate project where it will never get merged on the original repository fork is the option to use.
Fork is not a Git operation and it is a functionality provided by the git hosting applications such as GitHub, BitBucket etc..
A fork is included with the current status of the object graph and the entire history up-to the time where the fork is made.
Git Hooks
This allows to configure actions upon events in git transactions such as committing, merging and pushing. All the git hook configurations are in .git/hooks and at the time of initiating Git, templates are copied from git installation template folder within the operating system with .sample extension. To activate the hook the .sample extension has to be removed on the file.
E.g.:- Restrict commit for a specific email address
- Rename pre-commit.sample to pre-commit on .git/hooks
- Add following condition in BASH commands

Figure – 38.0 – restrict commits to a specific email of a user
If anything exist with 0, the rest will be passed and else git will identify it as an error and block the commit.
In figure 38.0 commits will be restricted to email : thisara@mail.com and if any other user with different email following error will be displayed to the developer.

Figure – 39.0 – users other than specified are blocked with error message
Hooks are really useful to invoke external systems upon Git events where as to initiate Continuous Integration and Continuous Delivery pipelines.
Git Revert
As discussed above git cannot traverse back to previous object due to the nature of DAG. However Git has git revert command which could be used to revert a particular commit. Let’s verify what is the object behaviour in this scenario;
- vi firstfile.txt
- Add content : This is the first file
- git add firstfile.txt
- New blob object created : 5495a4
- git commit -m “adding first file” – (figure 40.0)
- New Commit object created : f8b4e7
- New Tree object created : 04418d
- Tree object referencing on 5495a4

Figure – 40.0 – new file committing details for firstfile.txt
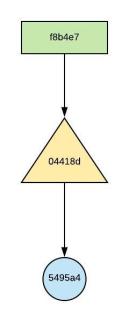 Figure – 41.0 – object referencing of the scenario executed in figure 40.0
Figure – 41.0 – object referencing of the scenario executed in figure 40.0
Let’s modify the file firstfile.txt and commit;
- vi firstfile.txt
- Add content : This is the first update.
- git add firstfile.txt
- New blob object created : bb6148
- git commit -m “executing first update” – (figure 42.0)
- New Commit object created : 571584
- New Tree object created : 09f1bd
- Tree object referencing on bb6148

Figure – 42.0 – update commit object details for firstfile.txt
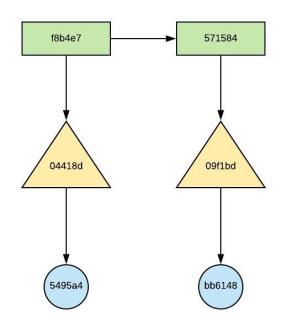 Figure – 43.0 – object relationship after firstfile.txt is updated
Figure – 43.0 – object relationship after firstfile.txt is updated
Let’s revert the final commit;
- git revert 574584 – (figure 44.0)
- Asks for adding message for revert (optional)
- Commit object created : 47c2ab
- Commit object pointing to 04418d Tree object

Figure – 44.0 – reverting the last update commit on the firstfile.txt
This does not remove the commit object and get back to the initial commit state, instead it creates a new Commit object and point to the initial Tree object as per DAG.
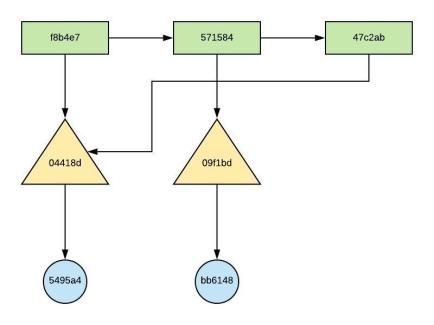 Figure – 45.0 – object relationship once after reverting the last update commit
Figure – 45.0 – object relationship once after reverting the last update commit
Pull Request
This enable code developer to get reviewed the code from peer developers to identify that anything is missed to achieve on defined standards of coding.
A developer could create a pull-request on the UI of the Git and it is possible to create pre defined templates to be populated on new PR to structure the content properly so that reviewer and developer will not lost any information.
Within the .github folder which maintains templates and user configurations such as repository owners. .github/ pull_request_template.md file content will populate on to each new PR created on the repository.
Once after the changes are being reviewed by the peers the code will get merged either via fast-forward or recursive strategy based on the commits of the branches.
Merging Branches
When the developments are conducted in multiple branches they would required to be merged at some point of time either to release or to maintain the repository updated.
There are two merging strategies available in Git such as;
Recursive Merge
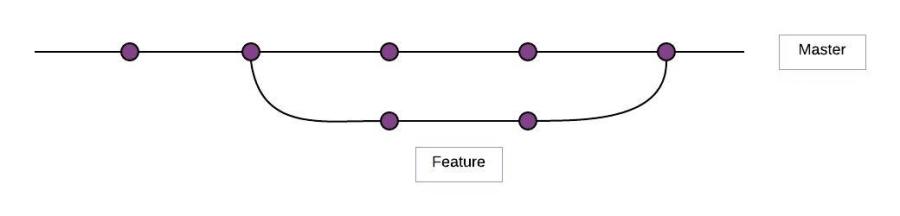
Figure – 46.0 – recursive merge pattern
When there are commits on both merging branches after the branch point, recursive strategy will be selected by git itself.
Let’s consider following two branches;
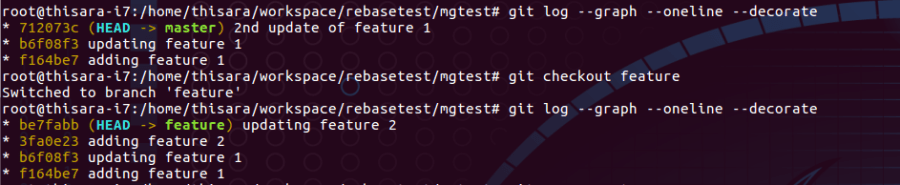
Figure – 47.0 – log of master and feature branches
Let’s merge master branch on to feature branch;
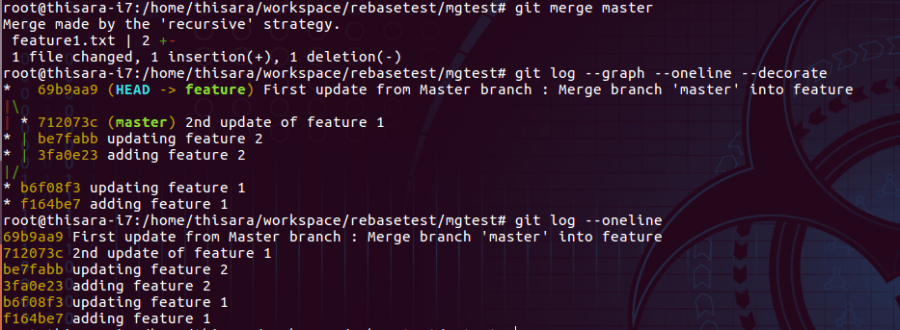
Figure – 48.0 – merge master branch on feature
As per the example in figure 48.0, recursive strategy is selected by Git itself and a new Commit object has been created with hash 69b9aa9.
The commit object is elaborated on figure 49.0 and it has two parents one from master and the other one from feature branch.

Figure – 49.0 – details of new merge object in recursive strategy
When merging changes on to feature branch from master or develop, this would not be an appropriate selection unless it is a public repository since this will reduce readability of history in feature branch due to the new commit object.
Fast Forward Merge
 Figure – 50.0 – fast-forward merge pattern
Figure – 50.0 – fast-forward merge pattern
When there are no changes on the master branch git will be selecting fast-forward branch by itself. A developer could override this by using –no-ff argument. However the appropriate option would be to use git rebase to get all the master branch commits on to feature branch and make it ready for fast-forward merge.
This is more convenient with private repositories and for public repositories merging commits after creating the branch would be a hectic task due to the amount of commits from a community.
This will create a clean and traceable history since there are no any additional commit objects are being created like in recursive merge.
Let’s consider figure 51.0 which rebase the master branch on to feature branch;
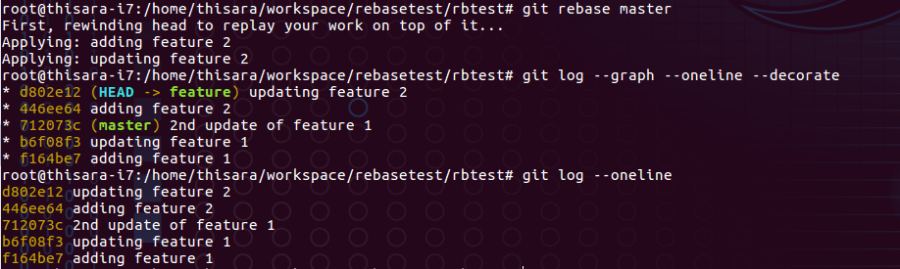
Figure – 51.0 – rebase master on feature branch
As per above, the HEAD is re-winded to the beginning of the branch to apply commits from master. The commit hashes are re-calculated and the references are being updated as 446ee64 : adding feature 2 which was on 3fa0e23 as per figure 47.0. This will create a new object reference hierarchy and link to the feature branch.
The order and the arrangement of the history of objects could be decided before execute the rebase passing the -i argument.

Figure – 52.0 – view log entries before rebase
This reflects the final state of the branch once after rebase is executed. The commit history could be arranged as required using the provided arguments as in figure 53.0. Since the update on be7fabb is a minor update / correction, let’s remove it getting logged on the feature branch.

Figure – 53.0 – alter log entries before merge
The history of feature branch would reflect as figure-54.0. Note the commit message for “updating feature 2” is not added on the history as per figure 54.0.

Figure – 54.0 – altered log after rebase master branch on feature branch
Now let’s merge feature branch on the master branch;
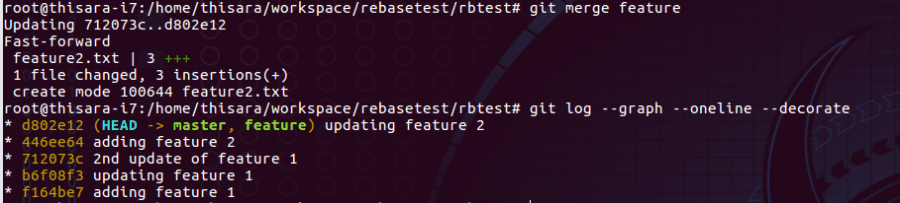
Figure – 55.0 – merge feature branch on master branch on fast-forward strategy
Since the master branch does not contain any commits after the feature branch point, fast-forward strategy is being selected by Git itself.
Merge conflicts
Conflicts would be presented when the changes done over multiple branches on the same file and they are not possible to merge without human intervention. In such situation the conflict has to be manually resolved.
Conflicts generated upon rebase;
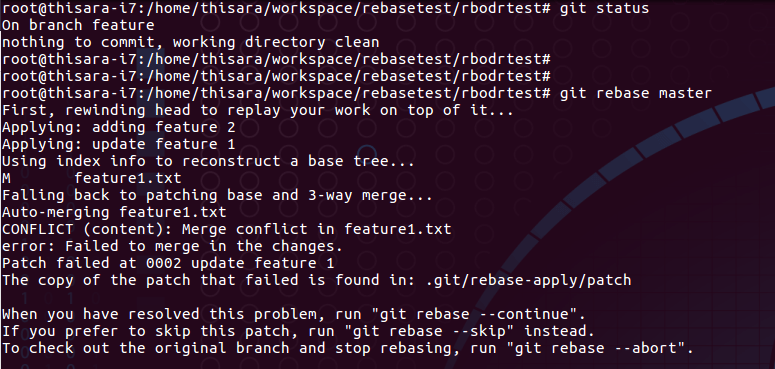
Figure – 56.0 – generated conflicts when rebase master on feature branch
The feature1.txt file would have conflict annotations to be resolved manually. The conflicts are reflected on the following format.
<<<<<<<< (destination file commit hash – 0c9844)
(Conflicting statement on the destination file)
======== (line break between origin and destination files)
(Conflicting statement on the origin file)
>>>>>>>> (commit message on the origin file)
E.g.:-

Figure – 57.0 – snapshot of conflicted file feature1.txt
Referring to the annotated numbers on figure 57.0;
(1) This is the beginning of the conflict. The commit hash is from feature branch referencing to feature1.txt file.
(2) The existing conflicting statement on feature branch which is the destination.
(3) This is the end of the conflicting statement block trailed with the last commit message.
Conflicts generated upon merge;

Figure – 58 .0 – generated conflicts when merge master on feature branch
Merge depicted on figure 58.0, would annotate conflicts on the feature1.txt file as in figure 59.0.

Figure – 59.0 – snapshot of conflicted file feature1.txt
The conflicts has to be resolved in the similar way as rebase, however since the commit is added on top of feature changes the conflict is started on current HEAD. Once the conflicts resolved it will add a new commit object along with the resolved files.
References
[1] https://danielkummer.github.io/git-flow-cheatsheet/
[2] https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow
[3] https://www.tollmanz.com/git-cherry-pick-range/
~ THE END ~
